
强化学习算法在控制领域的多元探索:从理论到MATLAB实现
强化学习算法,DDPG算法,在simulink或MATLAB中编写强化学习算法,基于强化学习的自适应pid,基于强化学习的模型预测控制算法,基于RL的MPC,Reinforcement learning工具箱,具体例子的编程。 根据需求进行算法定制: 1.强化学习DDPG与控制算法MPC,鲁棒控制,PID,ADRC的结合。 2.基于强化学习DDPG的机械臂轨迹跟踪控制。 3.基于强化学习的自适应控制等。 4.基于强化学习的倒立摆控制。
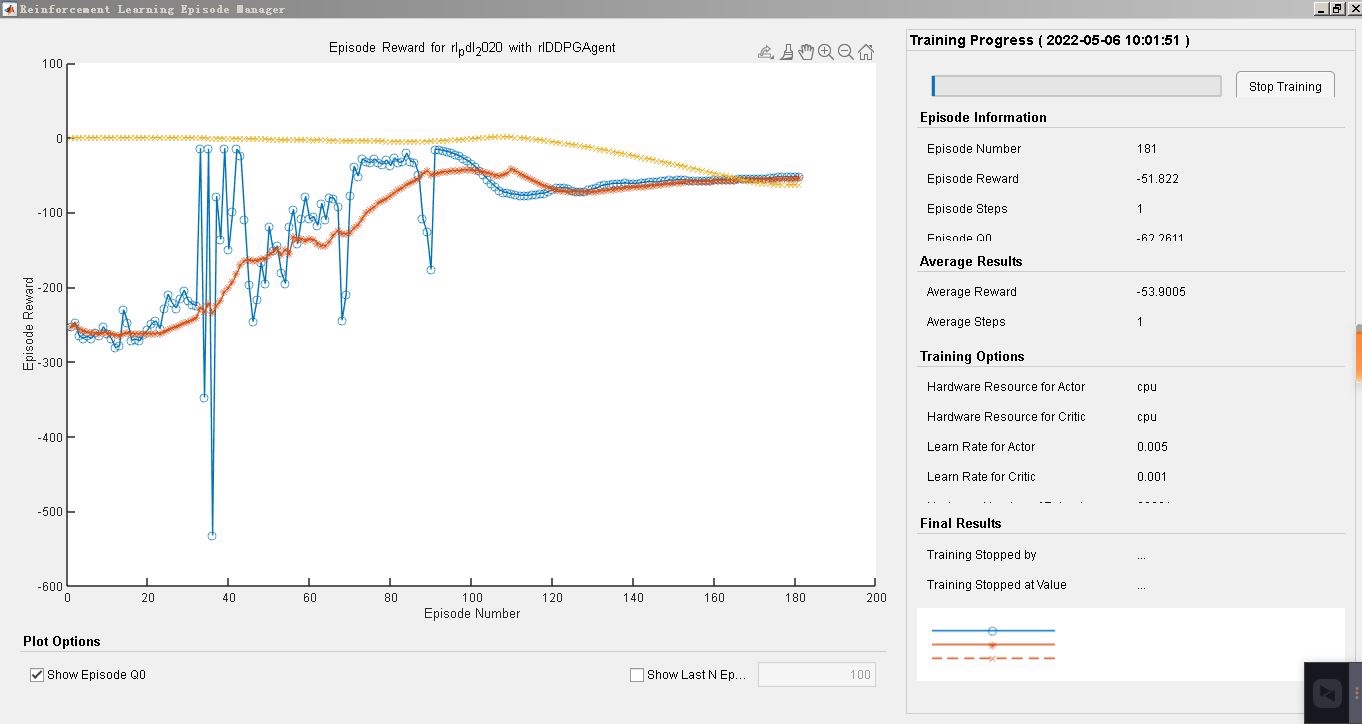
在控制领域,强化学习(Reinforcement Learning, RL)就像是一把万能钥匙,为我们开启了诸多传统控制方法难以触及的大门。今天咱们就来聊聊强化学习中的DDPG算法,以及它与多种控制算法的结合,还有在MATLAB中的具体实现。
强化学习DDPG算法
DDPG(Deep Deterministic Policy Gradient),简单来说,它是一种基于策略梯度的算法,能处理连续动作空间的问题。与传统的强化学习算法相比,DDPG的优势在于它可以直接输出一个确定的动作,而不是像某些算法那样输出动作的概率分布。
import tensorflow as tf
import numpy as np
# 定义DDPG网络中的Actor网络
class Actor(tf.keras.Model):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.l1 = tf.keras.layers.Dense(256, activation='relu')
self.l2 = tf.keras.layers.Dense(256, activation='relu')
self.mu = tf.keras.layers.Dense(action_dim, activation='tanh')
self.max_action = max_action
def call(self, state):
a = self.l1(state)
a = self.l2(a)
return self.max_action * self.mu(a)上面这段代码是简单的DDPG中Actor网络的Python实现。它接收状态作为输入,通过多层全连接神经网络,最终输出一个动作。这里面使用tanh函数将输出限制在[-1, 1]之间,再乘以max_action来得到实际的动作范围。
结合控制算法
1. DDPG与MPC、鲁棒控制、PID、ADRC的结合
- 与MPC结合:模型预测控制(MPC)的核心是基于系统模型预测未来的输出,并通过优化得到控制输入。将DDPG与MPC结合,DDPG可以学习到更优的控制策略来弥补MPC中模型不准确带来的问题。
- 与鲁棒控制结合:鲁棒控制旨在保证系统在存在不确定性的情况下仍能稳定运行。DDPG可以自适应地调整控制策略,与鲁棒控制结合能让系统在不确定性环境下更好地适应。
- 与PID结合:传统PID控制虽然简单有效,但对于复杂非线性系统表现不佳。基于强化学习的自适应PID控制,利用DDPG来动态调整PID的参数
Kp、Ki、Kd,让PID能更好地应对不同工况。
% 在MATLAB中基于RL的自适应PID参数调整示例
rl_env = rlFunctionEnv(@(state)pid_control(state));
actorOpts = rlRepresentationOptions('LearnRate',1e-3);
actor = neuralNetworkActorRepresentation(rl_env.ObservationInfo,rl_env.ActionInfo,'fc',[256 256],actorOpts);
criticOpts = rlRepresentationOptions('LearnRate',1e-3);
critic = neuralNetworkCriticRepresentation(rl_env.ObservationInfo,rl_env.ActionInfo,'fc',[256 256],criticOpts);
agentOpts = rlDDPGAgentOptions('SampleTime',0.01);
agent = rlDDPGAgent(actor,critic,agentOpts);这段MATLAB代码创建了一个基于函数的强化学习环境rl_env,用于自适应PID控制。然后定义了Actor和Critic网络,并设置了相关学习率等参数,最后创建了DDPG智能体agent。
- 与ADRC结合:自抗扰控制(ADRC)能对系统内外扰动进行估计并补偿。结合DDPG可以进一步优化ADRC的参数,提升控制性能。
2. 基于强化学习DDPG的机械臂轨迹跟踪控制
机械臂的轨迹跟踪控制一直是个难题,传统方法在面对复杂环境和高精度要求时显得力不从心。利用DDPG,机械臂可以通过不断试错学习到最优的轨迹跟踪策略。
% 假设机械臂模型已建立,这里只展示DDPG部分伪代码
numStates = 10; % 状态维度,例如关节角度、角速度等
numActions = 3; % 动作维度,例如关节力矩控制
env = rlCustomEnv(numStates, numActions); % 创建自定义环境
actorNet = [...
sequenceInputLayer(numStates)
fullyConnectedLayer(256)
reluLayer
fullyConnectedLayer(256)
reluLayer
fullyConnectedLayer(numActions)
tanhLayer];
actor = rlDeterministicActorRepresentation(actorNet,env.ObservationInfo,env.ActionInfo);
criticNet = [...
sequenceInputLayer([numStates numActions])
fullyConnectedLayer(256)
reluLayer
fullyConnectedLayer(256)
reluLayer
fullyConnectedLayer(1)];
critic = rlQValueRepresentation(criticNet,env.ObservationInfo,env.ActionInfo);
agent = rlDDPGAgent(actor,critic);这段MATLAB伪代码创建了用于机械臂轨迹跟踪控制的强化学习环境,以及DDPG的Actor和Critic网络,并最终生成了DDPG智能体。
3. 基于强化学习的自适应控制
自适应控制旨在让系统能根据环境变化自动调整控制策略。强化学习天生就适合做这件事,DDPG通过不断探索环境反馈,实时调整控制动作,实现自适应控制。
4. 基于强化学习的倒立摆控制
倒立摆是控制领域的经典问题。使用DDPG算法,智能体可以通过不断尝试不同的力来保持倒立摆的平衡。
import gym
import numpy as np
from ddpg_agent import DDPGAgent
env = gym.make('Pendulum-v0')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
agent = DDPGAgent(state_dim, action_dim, max_action)
for episode in range(1000):
state = env.reset()
total_reward = 0
for step in range(200):
action = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
agent.store_transition(state, action, reward, next_state, done)
agent.learn()
state = next_state
total_reward += reward
if done:
break
print(f'Episode {episode}: Total Reward = {total_reward}')这段Python代码使用gym库中的倒立摆环境Pendulum - v0,创建了DDPG智能体。在训练过程中,智能体不断尝试动作,存储经验并学习,以最大化奖励,也就是保持倒立摆平衡的时间。
MATLAB中的Reinforcement learning工具箱
MATLAB的Reinforcement learning工具箱为我们实现上述算法提供了极大的便利。它提供了各种预定义的环境、智能体模板以及训练函数。通过这个工具箱,我们可以快速搭建强化学习模型,无论是简单的倒立摆控制,还是复杂的机械臂轨迹跟踪。
% 使用MATLAB RL工具箱训练一个智能体的简单流程
env = rlPredefinedEnv('CartPole-Discrete');
agent = rlDQNAgent(rlQNetwork(env),rlDQNAgentOptions);
trainOpts = rlTrainingOptions('MaxEpisodes',500);
trainingStats = train(agent,env,trainOpts);这段代码使用了MATLAB RL工具箱预定义的CartPole离散环境,创建了一个DQN智能体,并进行训练。
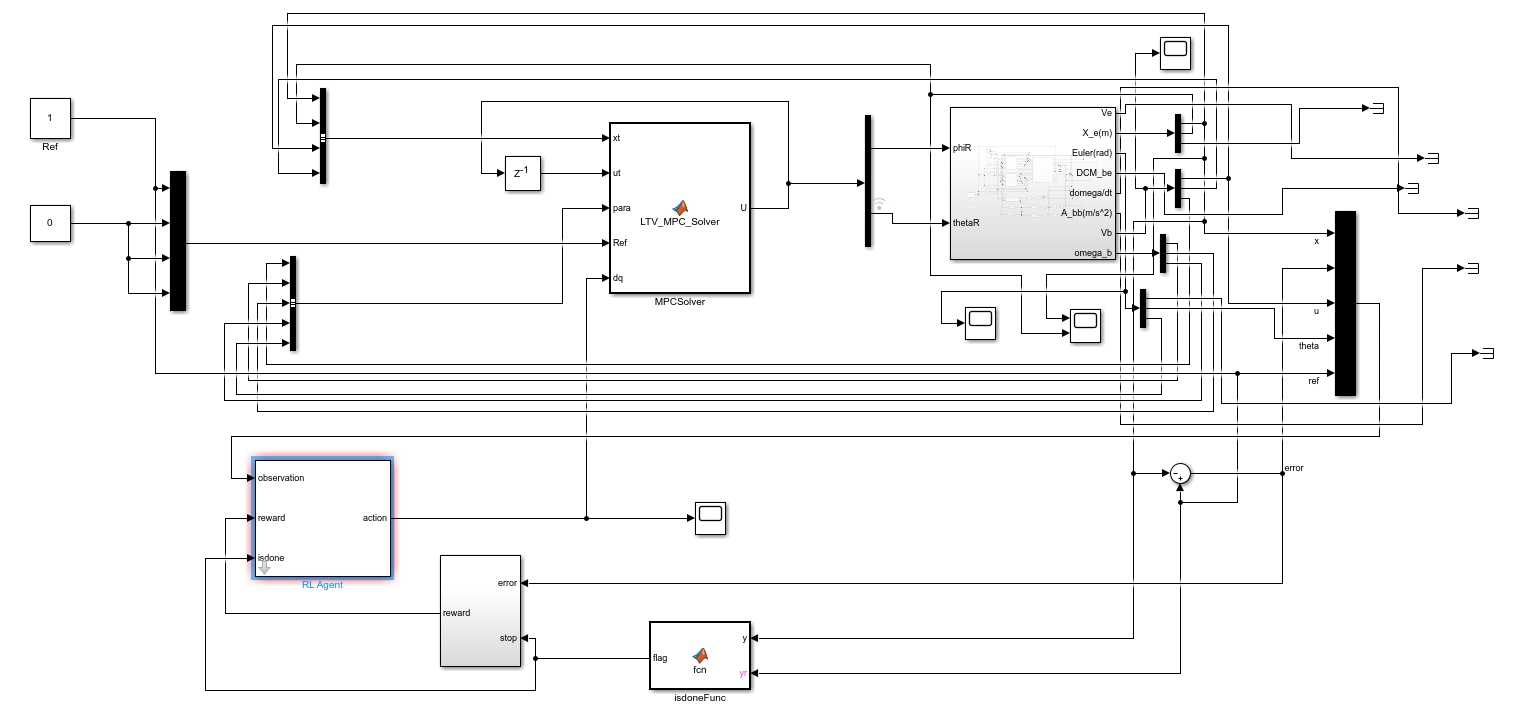
强化学习DDPG算法与各种控制算法的结合,以及在MATLAB中的实现,为控制领域带来了新的活力和解决方案。无论是复杂系统的控制,还是传统控制方法的优化,都有了更多的可能性。希望大家能在实际项目中尝试这些方法,创造出更优秀的控制系统。

更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)