
RTDETR 多模态目标检测全解析:从原理到实践(RGB + IR)
多模态检测的必要性三大融合策略多模态数据准备方式RTDETR 多模态结构设计完整可运行代码训练方法与优化策略跨模态 Transformer多模态自蒸馏轻量化多模态检测器多模态目标检测将在夜间检测、安防监控、自动驾驶等领域持续发挥重要作用。
摘要
RTDETR(Real-Time DETR)作为实时 Transformer 检测器,在速度与精度上取得了优异的平衡。
但在夜间、雾天、逆光等恶劣环境中,单模态 RGB 图像常常表现不稳定。
多模态目标检测(RGB + IR)利用多传感器信息互补,可显著提升检测稳健性。
本文围绕 RTDETR 多模态目标检测,从原理到代码实现全流程讲解:
- 多模态为什么重要?
- 三种多模态融合方式
- 数据集组织方式
- 多模态 RTDETR 网络结构
- PyTorch + Ultralytics 完整代码示例
- 训练方式与性能优化
适用于:行人检测、自动驾驶、安防监控、夜间检测等方向。
📚 目录
- 1. 引言:为什么需要多模态目标检测?
- 2. 多模态融合方式综述
- 3. 多模态数据集与数据组织方式
- 4. RTDETR 多模态检测方法
- 5. RTDETR 多模态实现代码(PyTorch + Ultralytics)
- 6. 训练示例与配置
- 7. 性能优化策略
- 8. 总结与展望
1. 引言:为什么需要多模态目标检测?
在复杂环境下,可见光 RGB 常会出现信号衰减或噪声过大,而红外 IR 具有以下优势:
| 场景 | RGB 弱点 | IR 优势 |
|---|---|---|
| 夜间 | 噪声大、看不清 | 能清晰捕捉人体/车辆热成像 |
| 雾霾 | 场景模糊 | 具有较强穿透性 |
| 逆光 | 强光导致识别失败 | IR 不受光照影响 |
| 遮挡 | 纹理细节缺失 | 边缘信息增强 |
因此,多模态融合可以显著改善检测鲁棒性。
2. 多模态融合方式综述
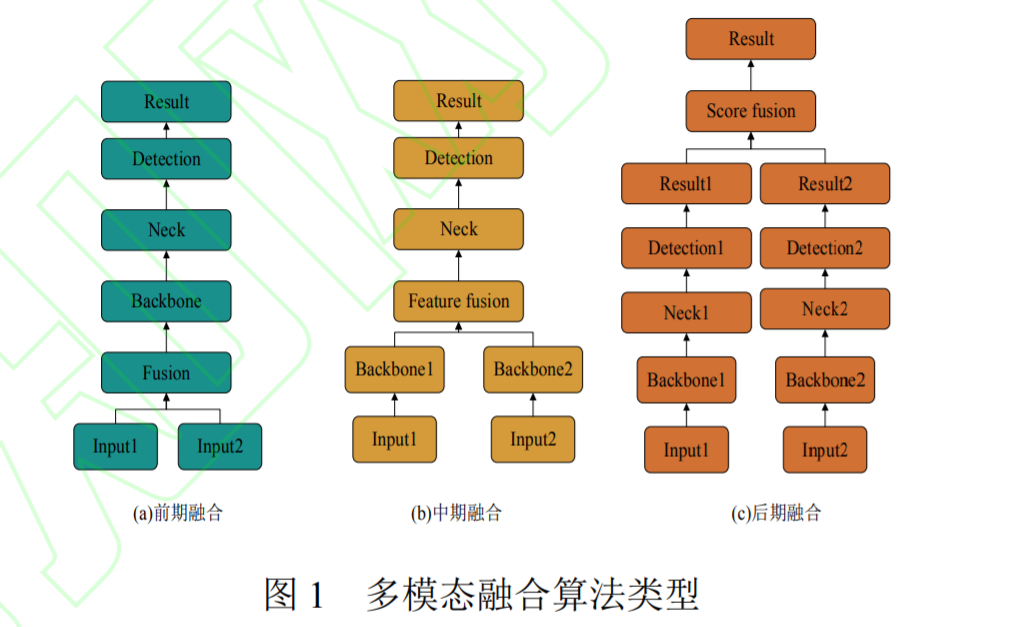
2.1 早期融合(Early Fusion)
将 RGB + IR 拼接为多通道输入,例如:
RGB: 3 通道
IR : 1 通道
→ 拼接为 4 通道输入
优点: 结构简单
缺点: 模态差异大,效果通常较弱
2.2 中期融合(Feature-level Fusion)⭐(最佳方案)
流程:
- RGB → Backbone_vis
- IR → Backbone_ir
- 在 Neck 或 Transformer Encoder 前融合特征
常见融合方式:Add / Concat / Attention
⭐ 实践中表现最稳定,也是本文重点介绍的方法。
2.3 晚期融合(Late Fusion)
RGB 与 IR 各自完成检测 → 再做结果融合。
缺点: 推理慢、计算量大
优点: 模型独立性强
3. 多模态数据集与数据组织方式
1️⃣ LLVIP
任务类型:弱光环境下的行人检测(RGB + IR)
模态:可见光 Visible、红外 Infrared
特点:夜间弱光场景、成对图像对齐,适合检测与图像融合任务
2️⃣ M3FD
任务类型:多场景行人/目标检测
模态:RGB + IR
特点:包含白天、夜晚、雾霾、强光等复杂条件,是鲁棒性研究常用数据集
3️⃣ KAIST Multispectral Pedestrian Dataset
任务类型:行人检测(RGB + 热成像 LWIR)
特点:多光谱检测领域最经典的基准数据集,数据量大、标注规范,被大量研究引用
4️⃣ FLIR ADAS Dataset
任务类型:自动驾驶感知
模态:可见光 + 热成像红外
特点:真实道路场景,适用于车辆、行人检测及自动驾驶领域多模态融合研究
5️⃣ VEDAI Dataset
任务类型:航拍车辆检测
模态:RGB + IR
特点:包含多种车辆类型,适合小目标检测、多模态融合算法研究
📁 多模态数据集统一结构样例(与你的截图一致)
用于 YOLO、Transformer、Diffusion 多模态训练的常见目录结构如下:
dataset/
├── images/ # 可见光(RGB)图像
│ ├── train/
│ └── val/
├── images_ir/ # 红外(IR)图像
│ ├── train/
│ └── val/
├── labels/ # YOLO 标注文件
│ ├── train/
│ ├── val/
│ ├── train.cache
│ └── val.cache
└── data.yaml # 数据配置文件
注意:
visible和images_ir必须同级- 文件名必须一一对应
- 标签只需提供一次(通常使用 RGB 的)
4. RTDETR 多模态检测方法
4.1 RTDETR 结构回顾
RTDETR 由以下部分组成:
- CNN + CSP Backbone
- Hybrid Transformer Encoder
- DETR-style 解码器
因为有 Transformer 模块,所以更适合处理多模态融合。
4.2 多模态 RTDETR 架构设计
总体框架:
RGB → Backbone_vis → Feature_vis
IR → Backbone_ir → Feature_ir
Feature_fused = Fuse(Feature_vis, Feature_ir)
→ Transformer Encoder
→ Decoder
→ Detection Output
4.3 特征融合策略
① Add 融合(最快、最常用)
fused = f_vis + f_ir
② Concat 融合(更强表达能力)
fused = torch.cat([f_vis, f_ir], dim=1)
③ Attention 融合(性能最强)
可加入:
- SE
- CBAM
- SimAM
- Cross Attention
5. RTDETR 多模态实现代码(PyTorch + Ultralytics)
5.1 双模态 Backbone
class DualBackbone(nn.Module):
def __init__(self, backbone_cls):
super().__init__()
self.backbone_vis = backbone_cls()
self.backbone_ir = backbone_cls()
def forward(self, x_vis, x_ir):
feat_vis = self.backbone_vis(x_vis)
feat_ir = self.backbone_ir(x_ir)
fused_feats = [v + i for v, i in zip(feat_vis, feat_ir)]
return fused_feats
5.2 多模态 RTDETR 结构
class RTDETR_Multimodal(nn.Module):
def __init__(self, pretrained="rtdetr-l.pt"):
super().__init__()
base = RTDETR(pretrained).model
self.backbone = DualBackbone(lambda: base.backbone.__class__())
self.encoder = base.encoder
self.decoder = base.decoder
def forward(self, x_vis, x_ir):
fused_feats = self.backbone(x_vis, x_ir)
enc = self.encoder(fused_feats)
out = self.decoder(enc)
return out
5.3 模型测试
model = RTDETR_Multimodal("rtdetr-l.pt")
x_vis = torch.randn(1, 3, 640, 640)
x_ir = torch.randn(1, 3, 640, 640)
pred = model(x_vis, x_ir)
print("Output:", pred)
6. 训练示例与配置
训练命令:
yolo train \
model=rtdetr_multimodal.yaml \
data=llvip.yaml \
imgsz=640 \
batch=16 \
epochs=100 \
device=0
rtdetr_multimodal.yaml 需定义双输入结构。
7. 性能优化策略
✔ 1. 模态对齐
RGB/IR 必须空间对齐,否则融合失败。
✔ 2. 使用注意力融合
如:
- CBAM
- SE
- Cross Attention
✔ 3. 轻量化 Backbone
减少双分支计算量,例如:
- MobileNet
- ShuffleNet
- PPLCNet
✔ 4. 数据增强同步
RGB 与 IR 必须执行相同的增强(翻转、旋转等)。
8. 总结与展望
本文详细介绍了:
- 多模态检测的必要性
- 三大融合策略
- 多模态数据准备方式
- RTDETR 多模态结构设计
- 完整可运行代码
- 训练方法与优化策略
未来可拓展方向:
- 跨模态 Transformer
- 多模态自蒸馏
- 轻量化多模态检测器
多模态目标检测将在夜间检测、安防监控、自动驾驶等领域持续发挥重要作用。
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)