
斯坦福大学CS231n Lecture 1 笔记:一篇文章带你了解深度学习发展史
AI 领域的学科版图与跨学科支撑
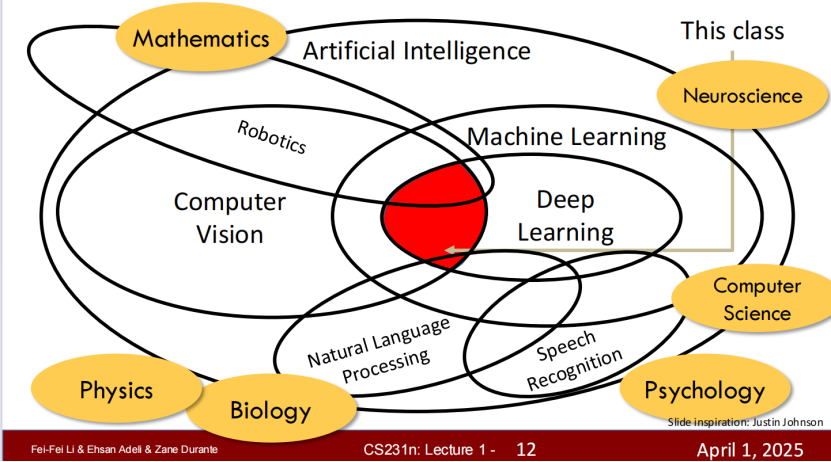
人工智能从来都不是一门孤立的学科,而是多领域交叉的智慧结晶。在 AI 的大框架下,机器学习是实现智能的核心方法,计算机视觉(CV)是 AI 最重要的应用分支之一,而深度学习则是机器学习的进阶形态,也是如今攻克计算机视觉问题的核心手段。
支撑这一切的,是数学、神经科学、计算机科学、生物学、心理学、物理学等多学科的合力:数学搭起算法骨架,神经科学揭秘人类视觉的底层逻辑,计算机科学实现技术落地,其他学科则从不同维度为机器 “看懂世界” 提供灵感,跨学科融合才让机器视觉的实现成为可能。
计算机视觉的源头:人类对视觉成像的千年探索
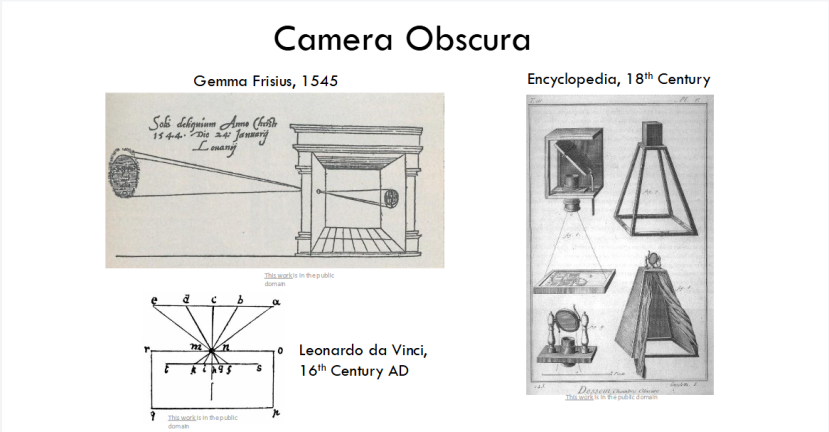
计算机视觉的诞生,始于人类对 “如何捕捉视觉” 的好奇与探索。早在 1545 年,Gemma Frisius 提出暗箱(Camera Obscura)原理,揭开了视觉成像的底层逻辑;16 世纪,达芬奇深入研究并完善这一原理,让人类对视觉成像的理解更深入;到了 18 世纪,暗箱原理被正式收录进百科全书,成为公认的视觉基础理论。
这些文艺复兴时期的探索,为几百年后计算机视觉的发展埋下了关键伏笔 —— 机器要 “看懂” 世界,首先要学会像人类一样捕捉、处理视觉信息,而暗箱原理,就是这一切的起点。
Hubel & Wiesel:解锁人类视觉的神经密码
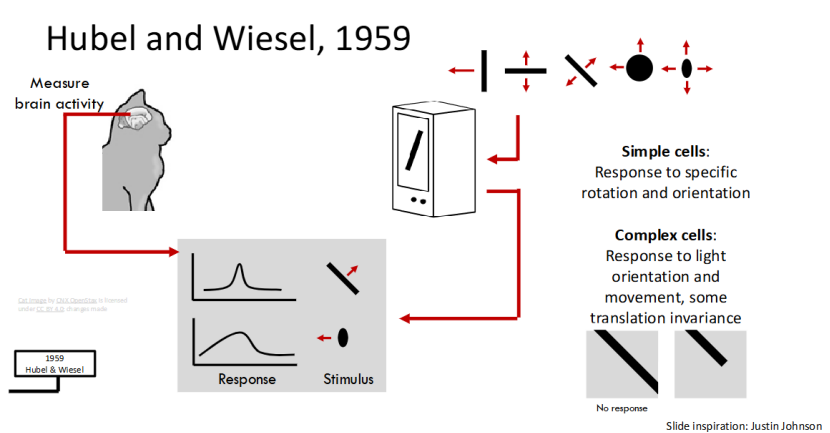
1959 年,Hubel 和 Wiesel 的经典实验,为计算机视觉打开了全新的思路。他们通过测量大脑活动发现,人类视觉系统中存在简单细胞和复杂细胞:简单细胞会对特定旋转、方向的视觉刺激做出反应,复杂细胞则能识别光线方向、物体运动,还具备部分平移不变性。
这一发现揭示了人类视觉皮层的神经元响应机制,是神经科学对计算机视觉最核心的启发,后续卷积神经网络(CNN)的核心结构,正是基于这个原理设计的,堪称机器视觉的 “生物学基石”。
Larry Roberts:机器首次尝试 “理解” 3D 视觉
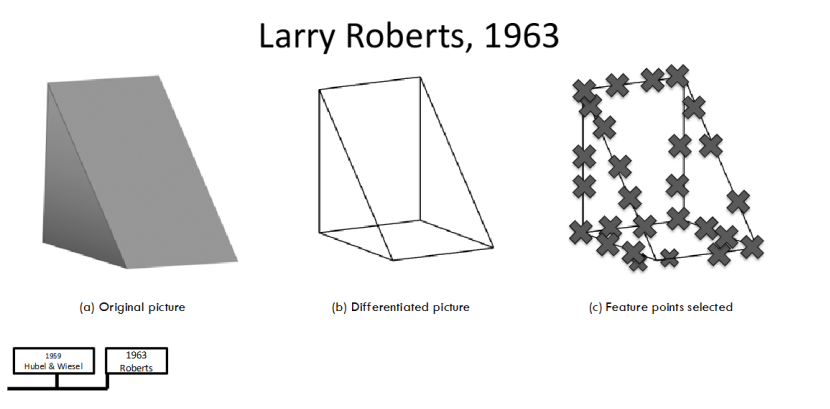
1963 年,Larry Roberts 发表的《Machine Perception of Three-Dimensional Solids》,是计算机视觉早期的开创性研究。他实现了从原始图像,到差分图像,再到特征点选择的完整流程,让机器第一次尝试 “感知” 3D 实体的视觉信息。
这一步看似简单,却迈出了机器从 “看见像素” 到 “提取特征、理解空间” 的关键一步,为后续 3D 视觉研究奠定了基础。
MIT 夏季视觉项目:计算机视觉正式成为研究领域

1966 年,MIT 的 PROJECT MAC 人工智能小组发起了 “夏季视觉项目”,由 Seymour Papert 主导。这个项目试图将视觉系统的复杂问题拆分成多个子问题,让研究者分工协作、独立开发,最终整合出一个完整的视觉系统。
这不仅是计算机视觉第一次迎来团队化、系统化的研究尝试,更标志着计算机视觉正式成为人工智能的一个独立研究领域,推动了模式识别技术的快速发展。
David Marr:建立计算机视觉的经典理论框架
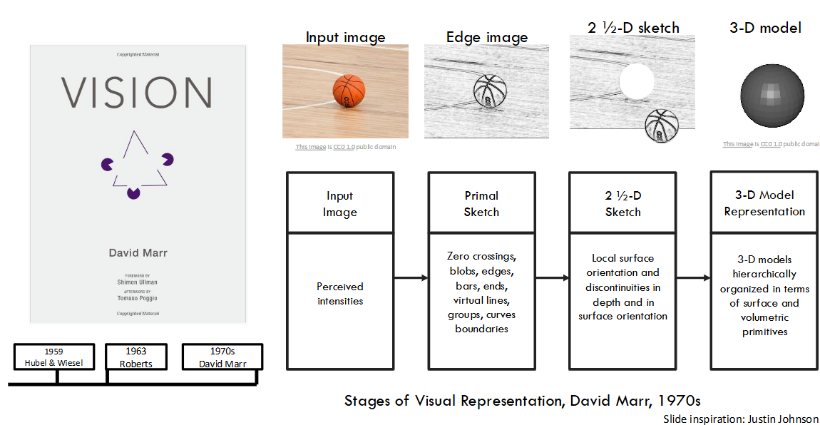
1970 年代,David Marr 提出的视觉表征三阶段理论,为计算机视觉搭建了第一个经典的理论框架,影响至今。他认为,人类的视觉处理过程分为三步:
- 原始草图:提取图像的边缘、斑点、线条等基础视觉特征;
- 2.5 维草图:感知物体的局部表面方向、深度和表面方向的不连续性;
- 3D 模型表示:将视觉信息转化为层级化的 3D 体积模型,实现对物体的立体理解。这一理论让机器视觉的研究有了清晰的路径,成为该领域的重要理论基石。
基于部件的识别:让机器像人一样 “拆解开看物体”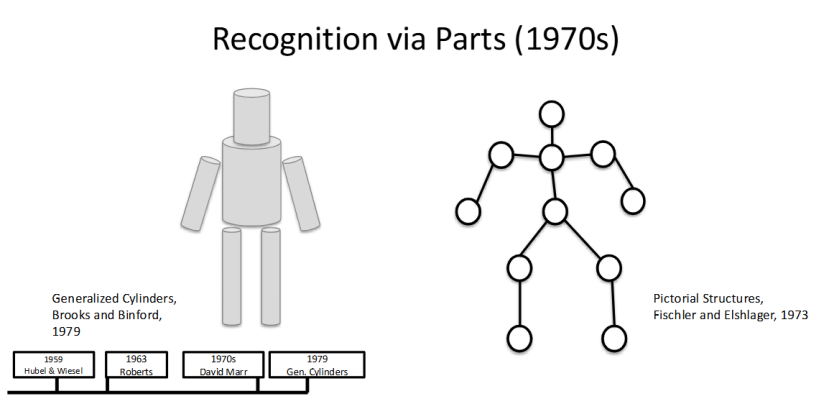
1970 年代,计算机视觉迎来了 “基于部件的识别” 方法,核心思路是将物体拆分为基础部件来识别,就像人类看东西会先分辨 “头、手、身体” 一样。
其中最具代表性的成果,是 1973 年 Fischler 和 Elshlager 的图形结构(Pictorial Structures),以及 1979 年 Brooks 和 Binford 的广义柱体(Generalized Cylinders),这种方法也成为了早期人体姿态识别、物体识别的核心手段。
边缘检测:计算机视觉的 “特征提取基本功”

1980 年代,计算机视觉进入了 “基于边缘检测的识别” 阶段,边缘检测也成为了机器提取视觉特征的核心基本功。1986 年 John Canny 提出的 Canny 边缘检测算法,以及 1987 年 David Lowe 的相关研究,让边缘检测的精度和效率大幅提升。
直到今天,边缘检测依然是计算机视觉的基础技术,在图像分割、特征提取、目标检测等任务中仍被广泛应用。
AI 寒冬:整体遇冷,但计算机视觉从未停止前进
这一时期,人工智能领域迎来了第一次 “寒冬”:由于 “专家系统” 未能兑现最初的预期,整个领域的研究热情和资金支持大幅锐减。
但值得注意的是,计算机视觉、自然语言处理、机器人学等 AI 子领域,并未因整体遇冷而停滞。研究者们依然在默默探索,为后续的技术爆发积累了大量理论和方法,这也成为了计算机视觉发展史上的重要转折。
RSVP 快速视觉感知实验:揭秘人类的 “极速视觉”
1970 年代,Potter 等人提出了快速序列视觉感知(RSVP)实验,探索人类处理视觉信息的速度极限。实验发现,人类能在极短的时间内识别图像内容,这种快速视觉感知的能力,让研究者对人类视觉系统的高效性有了新的认知。
这一研究补充了人类视觉感知的底层规律,也为机器视觉追求 “快速识别” 提供了重要参考。
人类视觉的 150 毫秒奇迹:比想象中更高效
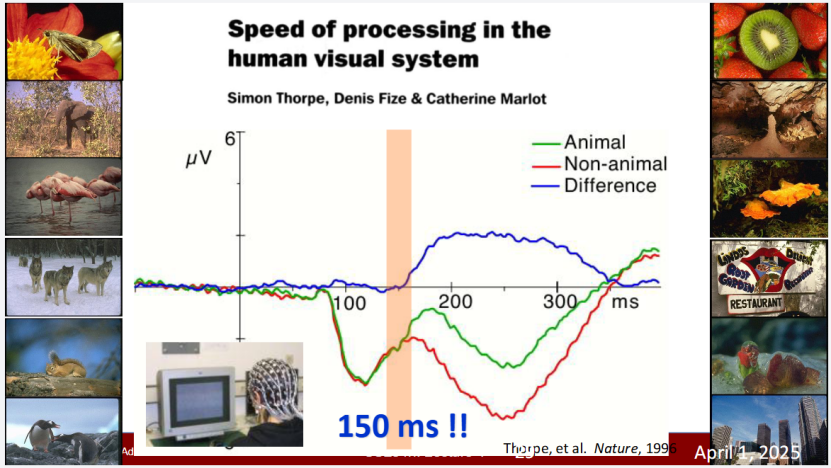
1996 年,Simon Thorpe 等人在《Nature》发表的研究,刷新了人类对自身视觉系统的认知:他们发现,人类视觉系统处理视觉信息、完成识别的速度仅需 150 毫秒,远超此前的所有预期。
这个 “150 毫秒奇迹” 揭示了人类视觉的极致高效性,也为机器视觉的研究树立了目标 —— 让机器尽可能接近甚至超越人类的视觉处理速度。
人类视觉的 “领域特异性”:大脑有专属 “视觉分区”
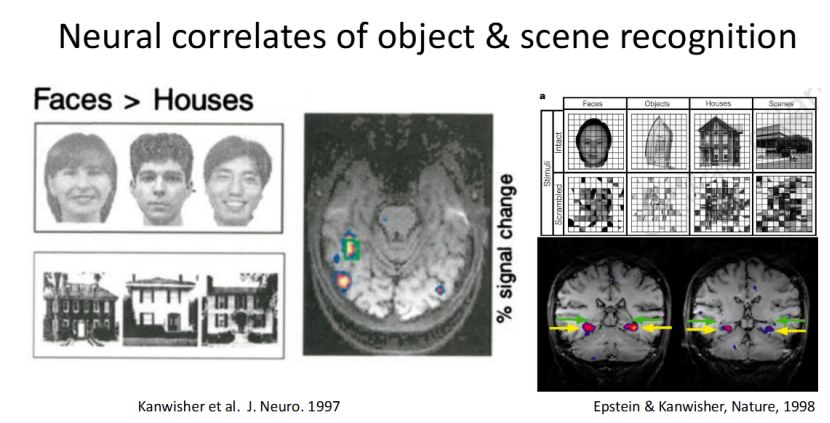
1997 到 1998 年,Kanwisher 等人的研究发现了人类视觉的神经相关性:大脑中存在专门处理特定视觉信息的区域,比如人脸识别脑区(FFA)对人脸的反应,远强于对房屋、物体的反应;Epstein 和 Kanwisher 的研究进一步验证了这一结论。
这说明人类视觉存在 “领域特异性”,这一发现也为机器视觉的 “专用模型” 设计提供了启发 —— 针对不同的视觉任务,设计专门的模型,能大幅提升识别效率。
视觉识别:视觉智能的核心基础任务

这张图传递了一个核心结论:视觉识别是视觉智能的基础。无论是人类还是机器,想要实现更复杂的视觉任务(比如理解场景、分析行为、生成图像),都必须先做好最基础的物体识别、场景识别,这也是计算机视觉研究的核心切入点。
归一化割(Norm.Cuts):让机器 “给图像像素分组”
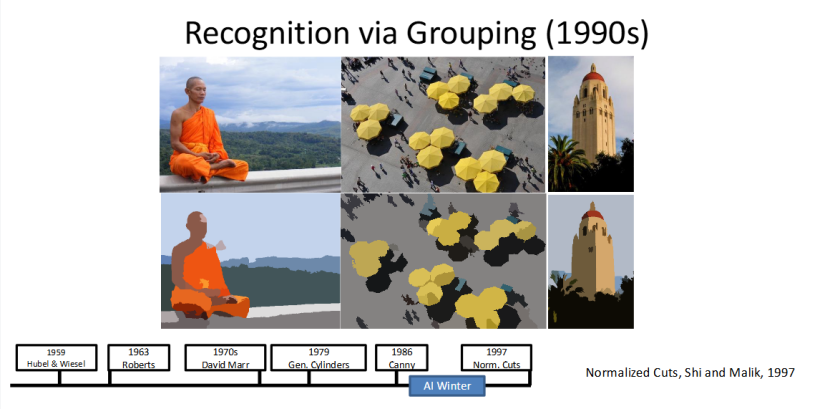
1990 年代,计算机视觉迎来了 “基于分组的识别” 方法,1997 年 Shi 和 Malik 提出的归一化割(Normalized Cuts) 是其中的代表。
它的核心思路是将图像的像素进行分组聚类,把相似的像素归为一类,通过这种方式提取图像的特征,实现物体和场景的识别,成为了 90 年代计算机视觉核心的特征提取技术之一。
SIFT 算法:计算机视觉的 “经典特征匹配神器”
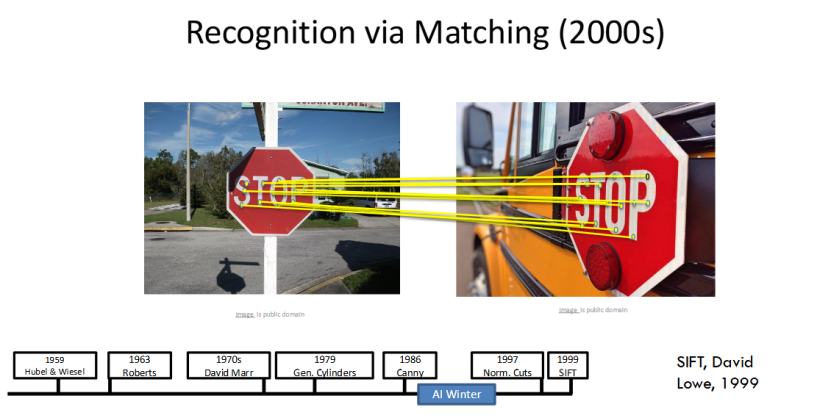
2000 年代,“基于匹配的识别” 成为主流,1999 年 David Lowe 提出的SIFT(尺度不变特征变换) 算法,堪称计算机视觉的 “经典特征匹配神器”。
它具备尺度、旋转不变性—— 无论图像被放大、缩小还是旋转,SIFT 都能提取到稳定的特征点,实现精准的图像匹配。直到今天,SIFT 依然在图像检索、目标匹配、全景拼接等任务中被广泛应用。
Viola-Jones 算法:机器学习首次成功落地计算机视觉
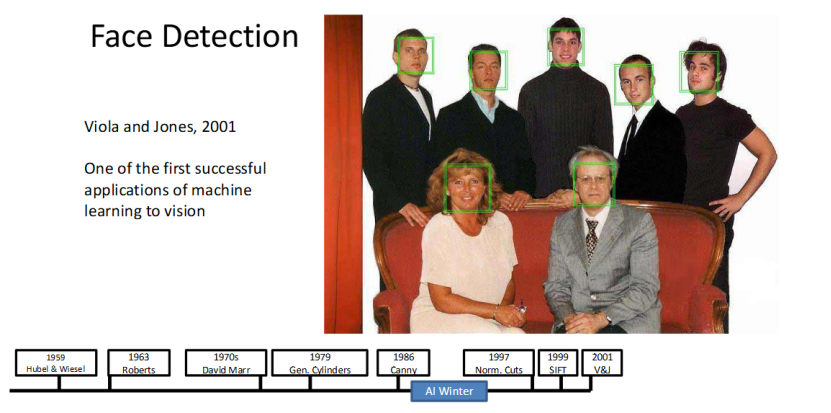
2001 年,Viola 和 Jones 提出的人脸检测算法,是机器学习首次成功应用于计算机视觉的经典案例,堪称里程碑式的突破。
这个算法实现了实时、高效的人脸检测,让机器能在复杂场景中快速找到人脸,不仅推动了机器学习与计算机视觉的深度结合,也为后续的目标检测研究奠定了基础。
Caltech 101 & PASCAL:让计算机视觉研究 “有标可依”

2004 年的 Caltech 101 数据集,和 2007 年的 PASCAL 视觉对象挑战,为计算机视觉研究解决了一个关键问题 ——没有统一的评测标准和数据集。
这两个成果提供了标准化的数据集和评测基准,让全球的研究者能在同一标准下验证算法效果,推动了计算机视觉领域的规范化发展,也为后续大规模数据集的出现埋下了伏笔。
感知机:深度学习的 “初代雏形”
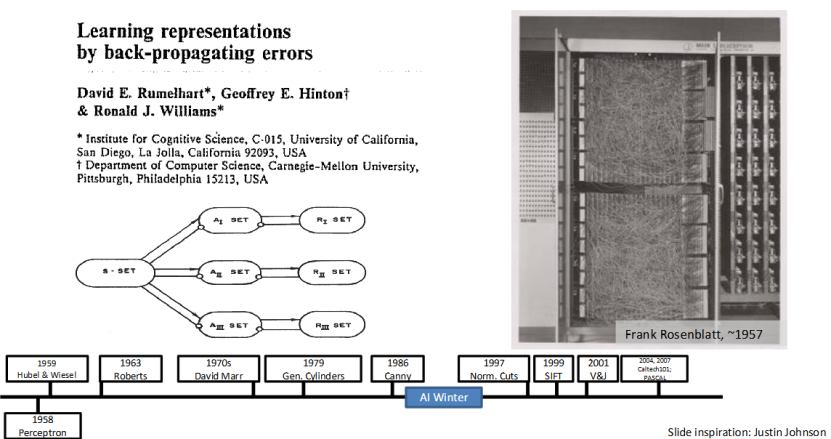
1958 年,Frank Rosenblatt 提出的感知机(Perceptron),是神经网络的初代雏形,也是深度学习的源头。它试图模拟人类神经元的工作方式,通过简单的线性运算实现二分类,为后续神经网络和深度学习的发展,奠定了最基础的结构框架。
感知机的局限:深度学习的第一次低谷
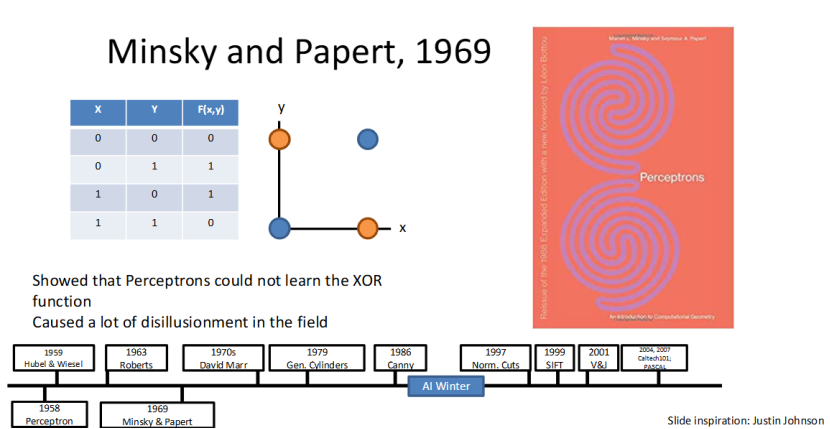
1969 年,Minsky 和 Papert 的研究给当时火热的感知机泼了一盆冷水:他们证明,单层感知机无法学习异或(XOR)函数,根本解决不了非线性分类问题。
这一发现让人们意识到了单层感知机的巨大局限性,整个神经网络领域陷入低谷,成为了深度学习发展史上的重要挫折,也让研究者们开始思考:如何突破线性限制,构建更复杂的网络。
新认知机(Neocognitron):CNN 的 “早期雏形”
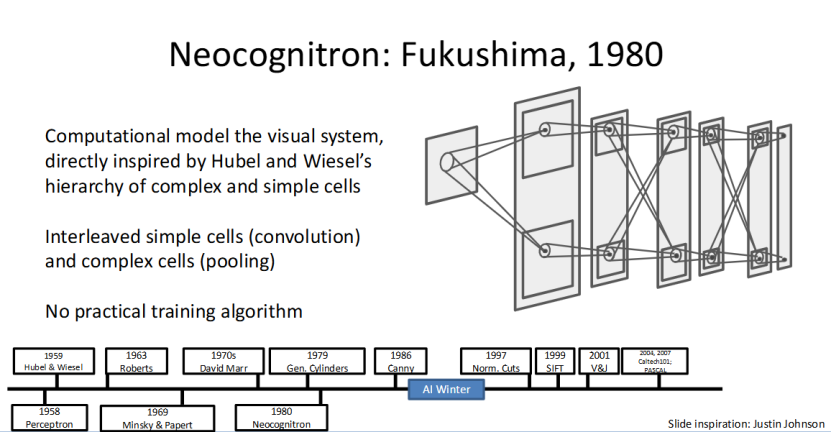
1980 年,Fukushima 提出的新认知机(Neocognitron),是卷积神经网络(CNN)的早期雏形,它的设计直接受 Hubel 和 Wiesel 的视觉细胞研究启发。
新认知机首次引入了卷积(模拟简单细胞) 和池化(模拟复杂细胞) 的核心结构,完美贴合人类视觉的处理逻辑。但遗憾的是,当时还没有实用的训练算法,无法充分发挥这个模型的能力。
反向传播算法:深度学习的 “核心训练密码”
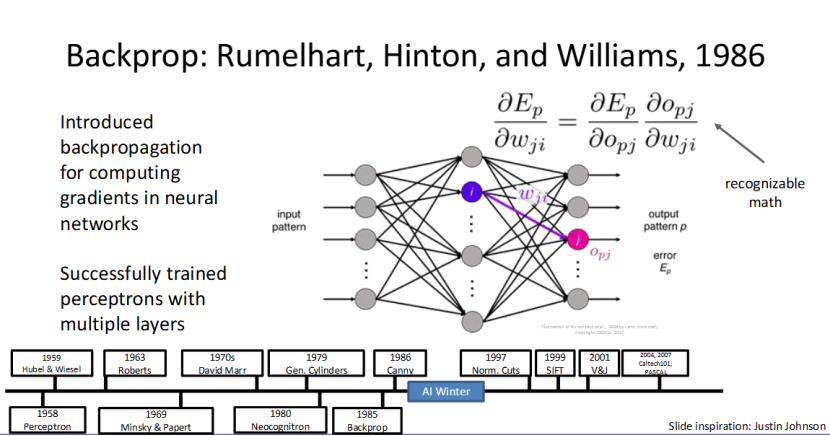
1986 年,Rumelhart、Hinton 和 Williams 提出的反向传播(Backpropagation) 算法,是深度学习发展的关键转折点,堪称深度学习的 “核心训练密码”。
它解决了多层神经网络的梯度计算问题,让研究者能通过反向传播误差,不断调整网络的参数,成功训练出多层感知机。这个算法的出现,为后续深度神经网络的训练奠定了核心基础。
LeNet:首个商用化的卷积神经网络
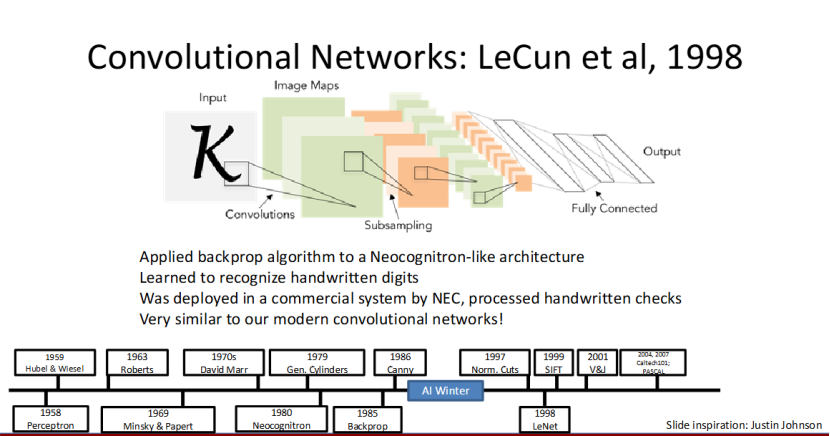
1998 年,LeCun 等人将反向传播算法应用于类新认知机架构,提出了经典的LeNet 模型,首次实现了手写数字的高精度识别。
更重要的是,LeNet 被 NEC 商用,用于处理手写支票,成为卷积神经网络首次商用化的案例。而且 LeNet 的结构和现代 CNN 高度相似,卷积、池化、全连接的组合,也成为了后续 CNN 的经典架构。
深度学习复兴:黎明前的探索
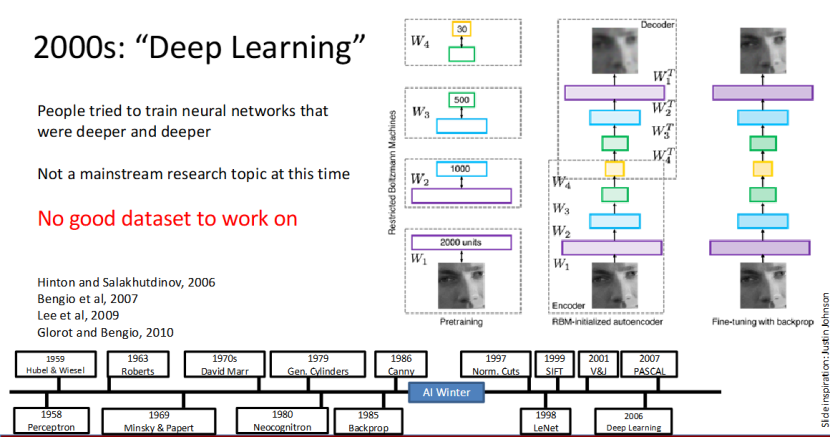
2006 年,Hinton、Bengio 等学者的研究,推动了 “深度学习” 概念的兴起,深度学习迎来了第一次复兴。研究者们开始尝试训练更深的神经网络,核心方法是基于 RBM 的预训练 + 反向传播微调,试图突破浅层网络的限制。
但此时的深度学习还并非主流研究方向,核心瓶颈有两个:缺乏高质量的大规模数据集,以及算力不足,无法支撑深层网络的训练,深度学习的爆发,还在等待一个关键契机。
ImageNet:深度学习的 “燃料库” 来了
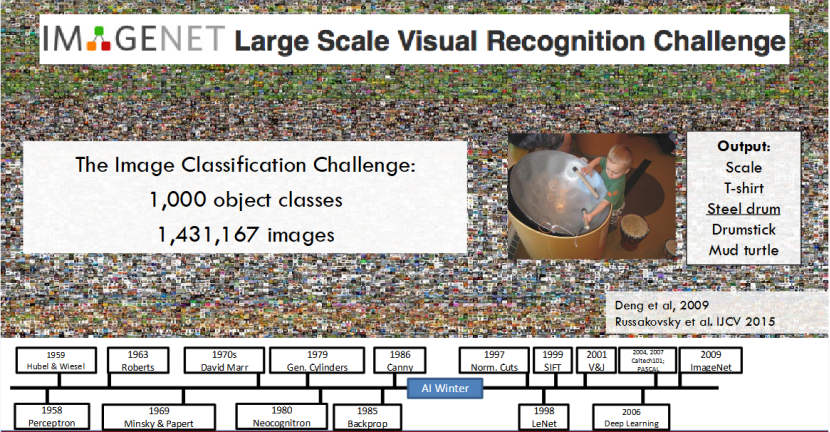
2009 年,ImageNet 大规模视觉识别挑战赛(ILSVRC)的发布,为深度学习的爆发解决了最关键的数据瓶颈,堪称深度学习的 “燃料库”。
这个数据集包含1000 个物体类别、143 万张标注图像,为深度模型的训练提供了标准化的大规模数据,让研究者终于有足够的 “素材”,去训练更深、更复杂的神经网络。
AlexNet:深度学习正式开启计算机视觉黄金时代
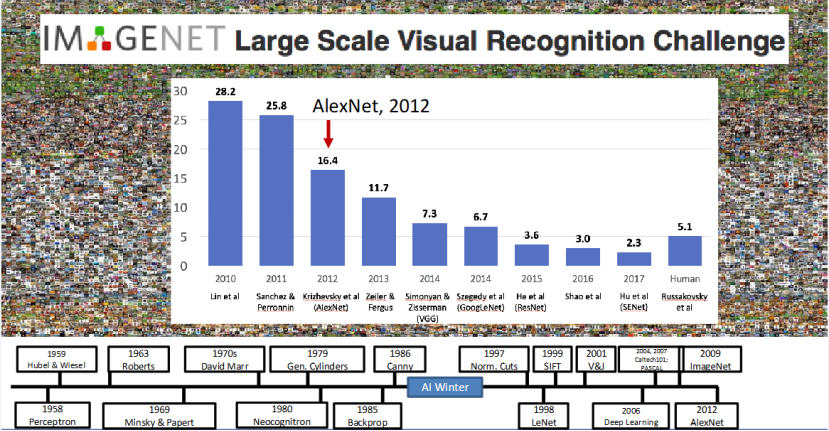
2012 年,Krizhevsky、Sutskever 和 Hinton 提出的AlexNet,在 ImageNet 挑战赛中以 16.4% 的错误率大幅领先第二名,创下了历史性的突破,也标志着深度学习正式成为计算机视觉的主流方法,开启了计算机视觉的深度学习黄金时代。
从这一年开始,深度学习彻底颠覆了传统的计算机视觉方法,成为了攻克视觉问题的核心手段。
AlexNet vs 新认知机:32 年的传承与进化
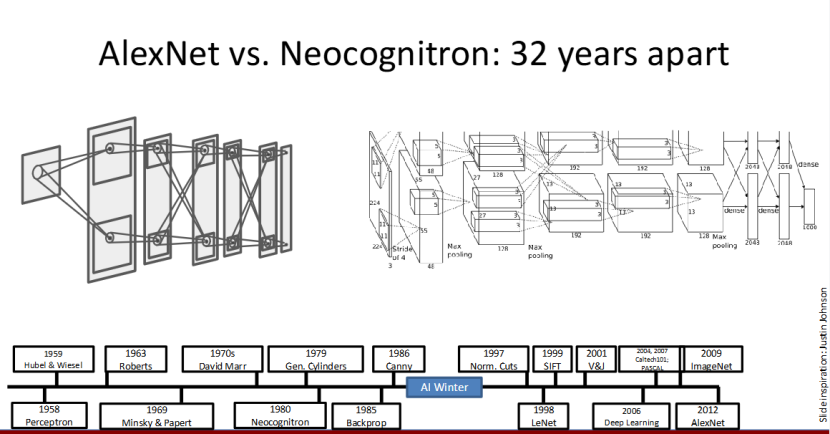
这张图对比了 2012 年的 AlexNet 和 1980 年的新认知机,时隔 32 年,两个模型的核心结构卷积 + 池化一脉相承,完美体现了计算机视觉和深度学习研究的延续性。
不同的是,AlexNet 有了反向传播算法的训练支撑,还有大规模数据集和算力的加持,能充分发挥卷积和池化的威力。这也印证了:早期的生物学启发和模型研究,为后续的技术爆发埋下了关键伏笔。
深度学习大爆发:学术界的 “井喷式发展”
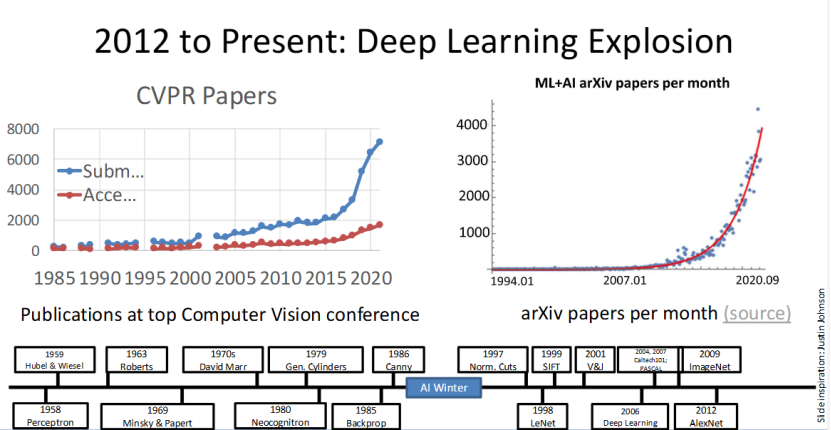
2012 年 AlexNet 的成功,点燃了深度学习的研究热情,此后计算机视觉迎来了井喷式的发展:从图中能清晰看到,CVPR(计算机视觉顶会)的论文数量从 1985 到 2020 年持续暴涨,ML+AI 领域的 arXiv 月投稿量也从 1994 年开始激增。
这组数据直观地反映了,2012 年后深度学习在学术界的爆发式发展,全球的研究者都开始投入到深度学习与计算机视觉的研究中。
技术迭代:深度学习颠覆传统计算机视觉
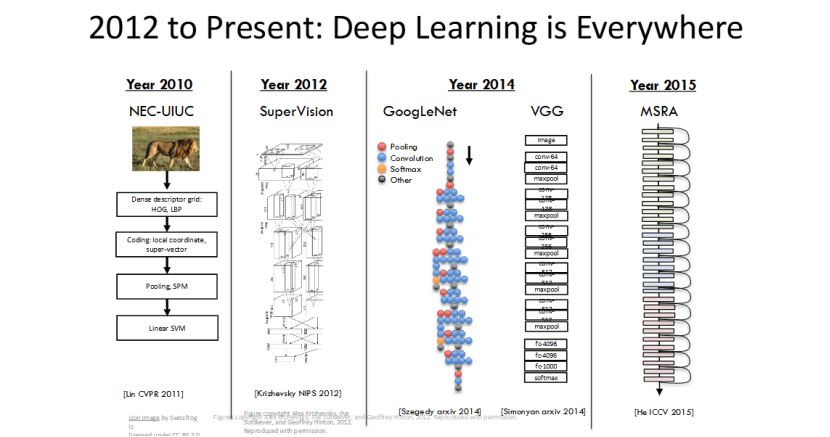
这张图展示了 2010 到 2015 年,计算机视觉主流方法的彻底迭代:2010 年,人们还在使用传统的 HOG/LBP 手工特征 + SVM 分类的方法;2012 年 AlexNet 出现后,深度 CNN 快速崛起;2014 到 2015 年,GoogLeNet、VGG 等经典深度模型相继出现。
短短 5 年,深度学习彻底颠覆了传统的计算机视觉方法,手工特征逐渐被深度模型自动提取的特征取代,成为了计算机视觉的新主流。
深度学习的细粒度识别:让机器 “分清相似的物体”

2012 年后,深度学习不仅提升了普通物体的识别准确率,更实现了细粒度识别—— 能精准区分外观高度相似的物体,比如豹、美洲虎、雪豹、猎豹,不同类型的摩托车、植物、水果等。
这种细粒度的识别能力,让机器的视觉识别精度大幅提升,接近甚至超越人类水平,也让机器能处理更复杂的视觉任务。
CV 应用大拓展:从图像分类到检测、分割
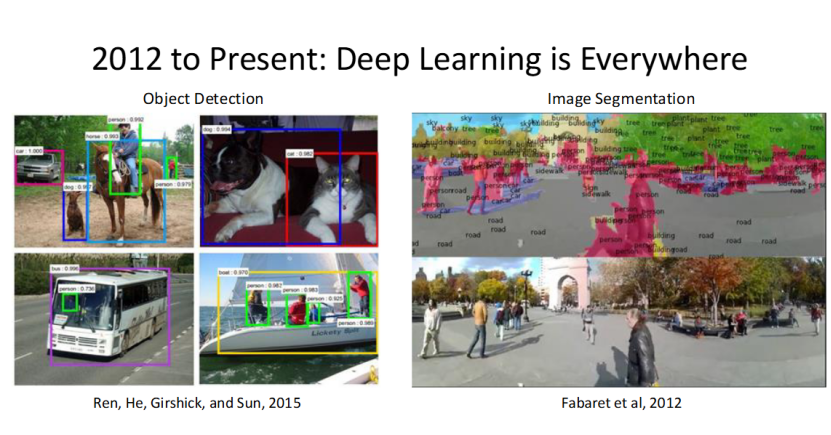
2012 年后,深度学习不仅提升了图像分类的效果,更推动了计算机视觉全领域的发展,应用范围从核心的图像分类,快速拓展到图像检索、目标检测、图像分割。
其中,Ren 等人 2015 年的目标检测成果,Fabaret 等人 2012 年的图像分割成果,成为了后续相关研究的经典基础,让机器从 “识别物体” 升级到 “定位物体、分割物体”。
CV 走进视频:从静态图像到动态视觉分析
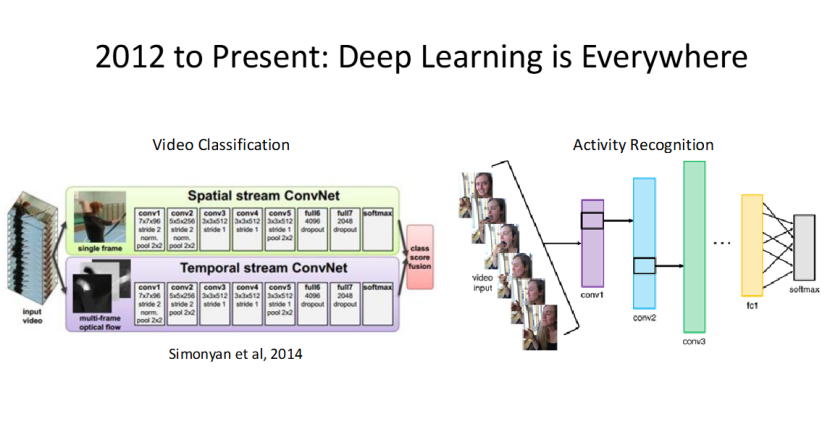
深度学习让计算机视觉的研究边界,从静态图像拓展到了动态视频,视频分类、行为识别成为了新的研究热点。
核心方法是 “空间流 CNN + 时间流 CNN”:空间流 CNN 处理单帧图像,提取空间特征;时间流 CNN 处理光流或多帧图像,提取时间特征,两者融合后,就能实现对视频中行为和动作的分析。
CV 的跨界融合:从 “看” 到 “理解行为”

深度学习让计算机视觉的能力进一步升级,从单纯的 “识别物体”,发展到理解动作和行为,还实现了与强化学习的跨界融合。
比如 2014 年的姿态识别技术,能精准检测人体的关节和姿态;同时,结合强化学习后,机器能通过视觉分析玩 Atari 游戏,根据游戏画面做出决策,实现更复杂的视觉任务。
CV 的行业落地:从实验室走向真实世界
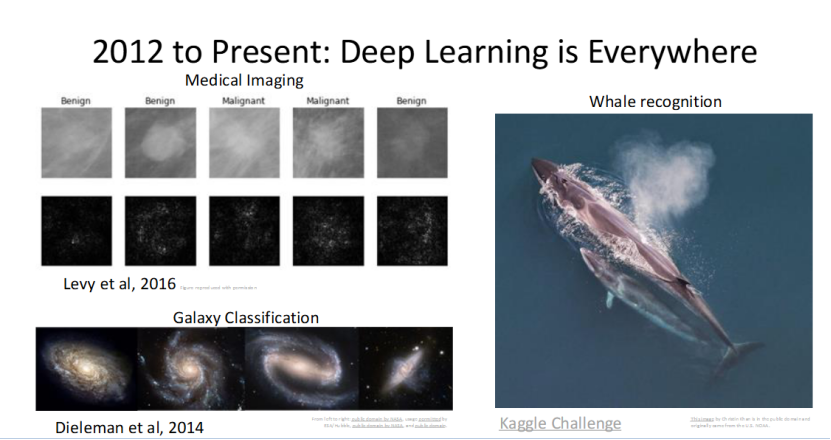
深度学习让计算机视觉走出实验室,真正落地到各行各业的真实场景中:医学影像领域,能精准识别肿瘤的良恶性;天文领域,实现星系的自动分类;生态领域,通过鲸鱼识别实现物种保护(Kaggle 经典挑战赛)。
这些应用充分体现了深度学习 + 计算机视觉的实际价值,让机器视觉成为解决行业问题的有力工具。
CV+NLP:让机器 “看得到,也说得出”

深度学习推动了计算机视觉(CV)与自然语言处理(NLP)的跨领域融合,图像描述(Image Captioning)技术应运而生,代表研究者有 Vinyals、Karpathy 和李飞飞等人。
这个技术让机器不仅能 “看” 懂图像内容,还能将其转化为通顺的文字描述,实现了 “图像→文字” 的生成,开启了人工智能多模态融合的研究方向。
视觉关系理解:让机器 “看懂图像的深层语义”
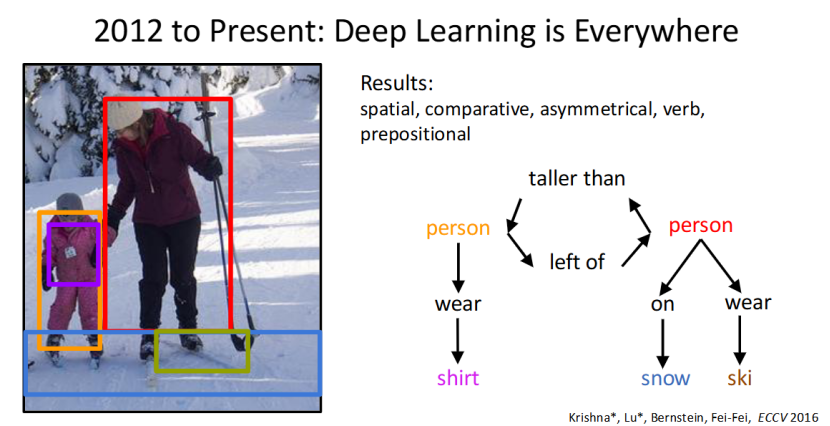
如果说图像描述是让机器 “说清图像内容”,那么 Krishna 等人 2016 年的视觉关系理解技术,就是让机器看懂图像的深层语义。
机器能识别图像中物体之间的空间关系、比较关系、动作关系,比如 “A 比 B 高”“A 在 B 的左边”“A 穿着衬衫”“A 在滑雪”,从单纯的物体识别,升级到了场景和关系的理解。
风格迁移:计算机视觉的 “创意玩法”

深度学习也让计算机视觉有了充满趣味的创意应用,风格迁移就是其中的代表(Gatys 等人 2016 年、Mordvinsev 等人 2015 年)。
它能将一张图像的内容,与另一张图像的艺术风格完美融合,比如将普通照片转化为梵高、莫奈的油画风格,让机器成为了 “艺术创作者”,也体现了深度学习 + CV 的创意性和趣味性。
GAN 的进化:开启 “生成式 CV” 时代

2018 年,Karras 等人提出的GAN 渐进式生长方法,大幅提升了生成图像的质量和稳定性,推动了生成对抗网络(GAN)在计算机视觉中的广泛应用,正式开启了 “生成式 CV” 时代 。
从此,计算机视觉不再只是 “识别和理解图像”,还能 “生成高质量的图像”,为后续的图像生成、图像修复、超分辨率重建等任务奠定了基础。
DALL・E:文本到图像,多模态融合的里程碑


2021 年,OpenAI 推出的 DALL・E,实现了从文本提示到图像生成的突破,成为多模态融合的里程碑。
只需输入文字描述,比如 “牛油果形状的扶手椅”“桃子形状的扶手椅”,DALL・E 就能生成对应的高质量图像,让机器能根据人类的语言想象,生成全新的视觉内容,将深度学习在 “视觉生成” 领域的能力推向了新高度。
深度学习的成功三要素:数据、算法、计算
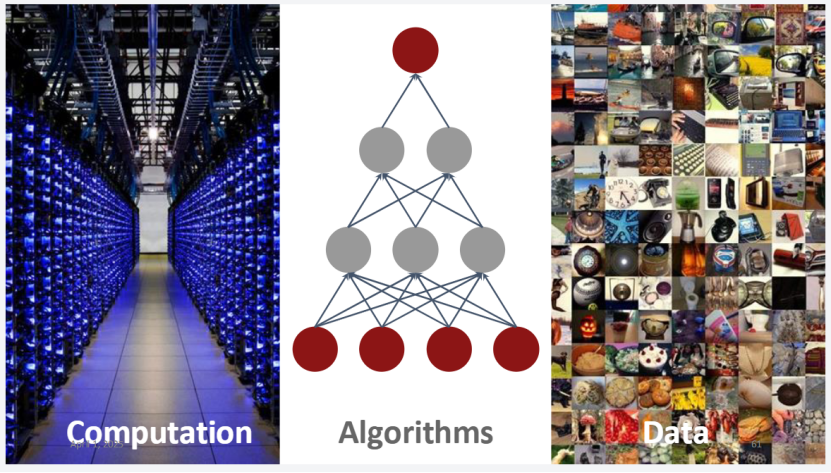
这张图揭示了深度学习爆发的核心密码:数据、算法、计算能力,三者缺一不可。
2006 年算法迎来复兴,2009 年 ImageNet 解决了数据瓶颈,而算力的持续提升(尤其是 GPU 的发展)则为深层网络的训练提供了硬件支撑。正是这三者的共同进步,才推动了深度学习的爆发式发展。
计算机视觉的伦理问题:警惕算法偏见
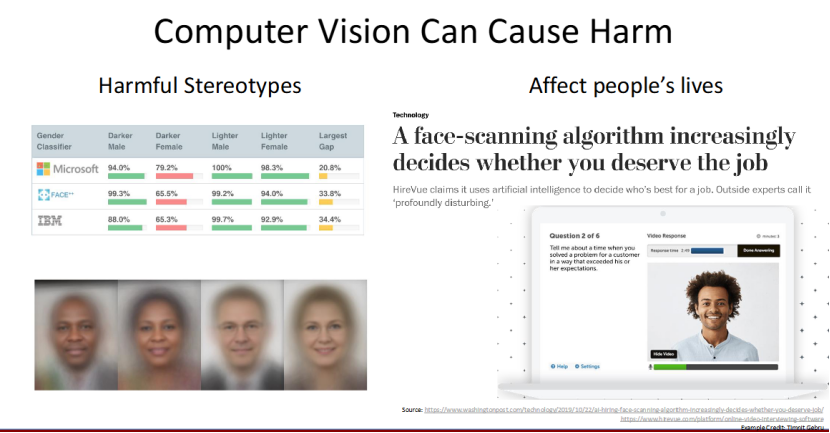
计算机视觉的发展并非只有光明,也存在需要警惕的伦理问题,其中最核心的就是算法偏见。
从图中的数据能看到,不同的性别分类器,对不同肤色人群的识别准确率差异巨大:比如 FACE *对深肤色女性的识别率仅 65.5%,对浅肤色男性却达 99.2%,差距高达 33.8%。更值得关注的是,这类算法已渗透到现实生活,比如 HireVue 的 AI 招聘面部扫描,可能会因偏见影响求职公平。这也提醒我们,发展技术的同时,必须重视 AI 伦理和算法公平性。
计算机视觉的温暖一面:拯救生命,改善生活

计算机视觉不仅有需要警惕的问题,更有能拯救生命、改善生活的温暖一面,在医疗、养老等领域发挥着重要作用:比如对新冠早期症状的检测,能实现早发现、早治疗;对慢性病患者的实时监测,能及时预警病情变化;对老年群体的安全照护,能监测摔倒、异常行为,保障老人安全。
这些应用充分体现了计算机视觉的社会价值,也是技术发展的最终意义 —— 让生活变得更好。
计算机视觉的未来:还有太多未知等待探索

尽管深度学习让计算机视觉取得了巨大进步,但这门学科依然有很长的路要走。
还有大量人类能轻松完成的视觉任务,机器至今无法实现,比如复杂场景的理解、抽象视觉的认知、跨场景的泛化等。这也意味着,计算机视觉的未来,还有太多的未知和挑战,等待研究者们去探索和突破。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)