
深度学习双雄:一文彻底搞懂梯度下降与反向传播
本文深入浅出地介绍了深度学习中两个核心概念:梯度下降和反向传播。梯度下降作为优化策略,通过计算损失函数的梯度方向寻找最优解,包含批量梯度下降、随机梯度下降和小批量梯度下降三种实现方式。反向传播则是计算梯度的具体算法,通过链式法则将误差从输出层反向传播至各层,高效计算出每个参数的梯度。两者协同工作,梯度下降确定优化方向,反向传播提供精确计算,共同构成了神经网络训练的基础。文章通过直观比喻和数学推导,
大家好!在踏入深度学习的宏伟殿堂时,有两个概念是我们无论如何也绕不开的“守门神”:梯度下降(Gradient Descent) 和 反向传播(Backpropagation, BP)。它们是驱动神经网络学习和优化的核心引擎,前者是战略方针,后者是战术执行。今天,就让我们用图文并茂、通俗易懂的方式,一次性征服这两个强大的概念!
一、战略方针:如何找到最优解?(梯度下降法)⛰️
在开始之前,我们先明确一个终极目标:训练一个神经网络,就是为了让它的预测结果与真实结果之间的误差(或称为损失,Loss) 尽可能小。
想象一下,这个“总误差”就像一座连绵起伏的山脉,我们的目标就是从山上的任意一个位置出发,走到山谷的最低点。而这个寻找最低点的“下山”策略,就是梯度下降法。
1. 核心思想:下山最快的一步
想象你被蒙上眼睛放在一座山上,要以最快的速度走到山谷底。你该怎么办?
最明智的做法是:伸出脚,试探四周哪个方向是“下坡最陡”的,然后朝着这个方向迈一小步。不断重复这个过程,你最终就能到达谷底。
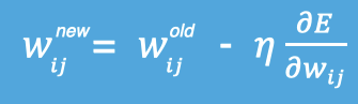
在数学中:
- “坡度” 就是梯度(Gradient)。
- 梯度的方向是函数值增长最快的方向。
- 那么,梯度的反方向自然就是函数值下降最快的方向。
因此,我们更新模型参数(比如权重 w)的公式就诞生了:
θnew=θold−η⋅∇J(θ) \theta_{new} = \theta_{old} - \eta \cdot \nabla J(\theta) θnew=θold−η⋅∇J(θ)
θ:代表模型的参数(权重和偏置)。η(eta):是学习率(Learning Rate),它决定了我们“下山”时每一步迈多大。- η 太小:步子太小,下山速度慢,训练时间长。🐢
- η 太大:步子太大,容易一步迈过山谷,在两边来回震荡,找不到最低点。😲
∇J(θ):是损失函数J(θ)关于参数θ的梯度。
2. 训练中的核心概念 🗓️
在进行模型训练时,我们经常遇到这三个名词:
- Epoch (轮次): 指的是使用全部训练数据对模型进行一次完整的训练。
- Batch Size (批大小) 📦: 每次训练,我们不用全部数据,而是取一小批(a batch of)数据来更新模型的参数。这个“一小批”的大小就是 Batch Size。
- Iteration (迭代) 🔄: 使用一个 Batch 的数据来完成一次参数更新的过程。
举个例子:
假设数据集有 50,000 个训练样本,我们设定 Batch Size = 256。
- 每个 Epoch 需要训练的样本数: 50,000
- 训练集包含的 Batch 数量: 50,000 / 256 ≈ 195.3,向上取整为 196 个。
- 每个 Epoch 的 Iteration 次数: 196
- 10 个 Epoch 总共的 Iteration 次数: 196 × 10 = 1960
3. 梯度下降的“三兄弟”
根据每次更新参数时使用的数据量不同,梯度下降法可以分为三种:
| 类型 | Batch Size | 优点 | 缺点 |
|---|---|---|---|
| 批量梯度下降 (BGD) | 全量数据集 N | 梯度准确,方向稳定,容易收敛到全局最优解 | 数据量大时,内存消耗大,训练速度极慢 🐢 |
| 随机梯度下降 (SGD) | 1 | 训练速度快,内存占用小,可能跳出局部最优解 | 梯度方向随机性大,收敛不稳定,震荡严重 🐇 |
| 小批量梯度下降 (Mini-Batch) | B (1 < B < N) | 结合了BGD和SGD的优点,速度和稳定性都很好 👍 | 需要额外选择Batch Size超参数 |
注:在现代深度学习中,Mini-Batch Gradient Descent 是最常用、最主流的方法。我们通常说的 SGD 很多时候其实指的就是 Mini-Batch SGD。
二、战术执行:如何计算梯度?(反向传播算法)⚙️
我们已经知道了要用梯度下降来更新参数,也知道了更新的公式。那么,现在最关键的问题来了:
在一个包含成千上万个参数的复杂神经网络中,如何高效地计算出每个参数的“梯度” ∇J(θ) 呢?
答案就是 —— 反向传播 (BP) 算法!
1. 核心思想:从后往前,层层追责
如果说梯度下降是“下山”,那么反向传播就是“计算下山坡度”的那个精密仪器。
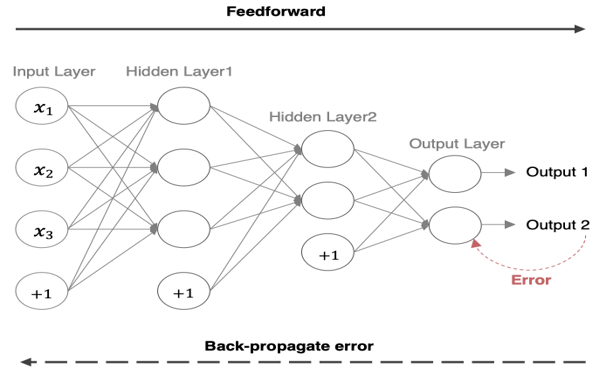
- 前向传播 (Forward Propagation) ➡️: 数据从输入层开始,逐层向前计算,直到输出层得到预测结果。就像多米诺骨牌一样,从第一块推倒最后一块。
- 反向传播 (Back Propagation) ⬅️: 计算预测结果与真实结果的误差,然后将这个误差从输出层开始,反向传播给网络中的每一层,并在此过程中利用链式法则计算出每个参数的梯度(即每个参数对最终误差的“贡献程度”)。
2. BP算法实战推演
让我们通过一个简单的神经网络来手动推演一遍 BP 的过程。
网络结构如下:(激活函数为 Sigmoid)
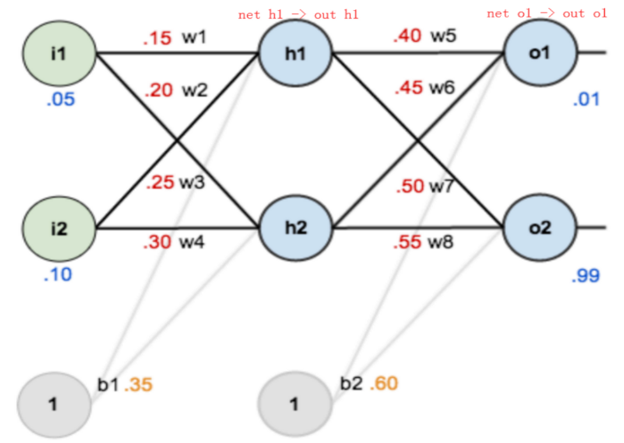
第一步:前向传播 ➡️
数据向前流动,计算出每一层的输出,最终得到预测结果。

第二步:计算总误差 🎯
假设真实标签是 [0.01, 0.99],我们使用平方和误差作为损失函数:
Etotal=∑12(target−output)2 E_{total} = \sum \frac{1}{2}(target - output)^2 Etotal=∑21(target−output)2
将前向传播计算出的值代入,得到总误差 E_total ≈ 0.29837。
第三步:反向传播 ⬅️
现在,我们开始反向计算梯度,以更新权重 w5 为例。这里就要祭出微积分中的大杀器 —— 链式法则 (Chain Rule) 🔗。
目标:计算 ∂E_total / ∂w5
E_total 受 out_o1 影响,out_o1 受 net_o1 影响,而 net_o1 直接受 w5 影响。因此,求导链条为:
∂Etotal∂w5=∂Etotal∂outo1×∂outo1∂neto1×∂neto1∂w5 \frac{\partial E_{total}}{\partial w_5} = \frac{\partial E_{total}}{\partial out_{o1}} \times \frac{\partial out_{o1}}{\partial net_{o1}} \times \frac{\partial net_{o1}}{\partial w_5} ∂w5∂Etotal=∂outo1∂Etotal×∂neto1∂outo1×∂w5∂neto1
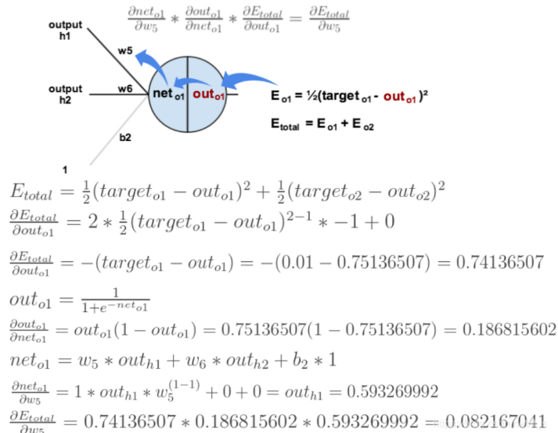
计算出梯度 ∂E_total / ∂w5 = 0.082167 后,我们就可以用梯度下降公式更新 w5 了:

对于更深层的权重(如 w1),链条会更长,但原理完全相同。w1 通过 out_h1 同时影响了 E_o1 和 E_o2,所以需要将两条路径的梯度相加。
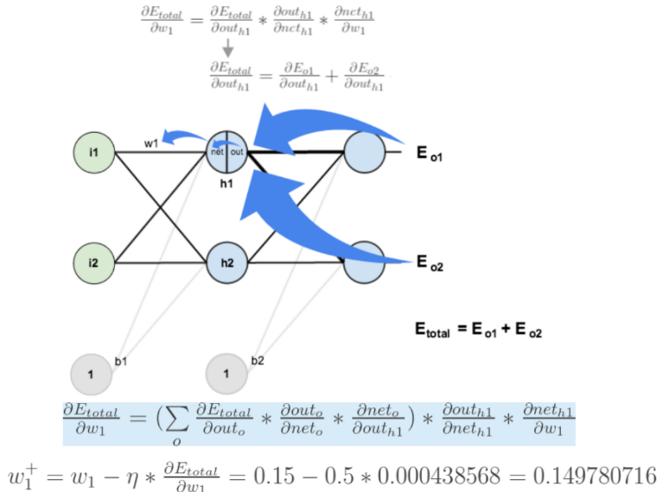
通过这样链式地、从后向前地计算,我们可以求出网络中每一个权重对总误差的偏导数(梯度),然后用梯度下降法统一进行更新。
三、总结:天作之合 ✨
最后,让我们用一句话来总结它们的关系:
梯度下降 就像是神经网络的“优化哲学”,它告诉我们:“为了让误差最小,我们应该朝着梯度的反方向去调整参数”。它回答了 “做什么 (What to do)”。
而反向传播 则是实现这一哲学的“精密算法”,它解决了“在一个复杂的网络中,如何高效、准确地计算出每个参数的梯度”这个关键问题。它回答了 “怎么做 (How to do it)”。
梯度下降是目标 (What to do),反向传播是方法 (How to do it)。两者相辅相成,构成了现代神经网络训练的基石。希望这篇文章能帮助你彻底理解这两个强大的概念!
🙏 课程推荐与参考 (Reference)
再次强调,本文核心知识点均提炼自 B 站黑马程序员 的精品课程,老师讲得非常详细,大家一定要去支持!
课程名称: AI大模型《神经网络与深度学习》全套视频课程,涵盖Pytorch深度学习框架、BP神经网络、CNN图像分类算法及RNN文本生成算法
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)