
CVPR‘26 开源| Rex-Omni检测万物:目标检测新范式
在这项工作中,我们介绍了Rex-Omni,一个拥有30亿参数的MLLM,它系统地解决了基于MLLM的目标检测所面临的挑战。关键的是,我们的分析验证了,虽然SFT提供了坚实的基础,但基于GRPO的后训练对于纠正SFT引发的行为缺陷(如重复和过大框预测)至关重要,这是构建鲁棒的基于MLLM的检测器的一项关键贡献。关键的是,Rex-Omni是在零样本设置下实现这一点的,这表明基于MLLM的检测方法在高度
点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
3D视觉工坊很荣幸邀请到了华南理工大学与IDEA研究院联合培养博士生蒋擎,为大家着重分享他们团队的工作。如果您有相关内容需要分享,欢迎文末联系我们。
 Detect Anything via Next Point Prediction
Detect Anything via Next Point Prediction
论文: https://arxiv.org/pdf/2510.12798
主页: https://rex-omni.github.io/
代码: https://github.com/IDEA-Research/Rex-Omni
直播信息
时间
2026年03月25日(周三)19:00
主题
CVPR'26开源| Rex-Omni 检测万物:目标检测新范式
直播平台
3D视觉工坊视频号
点击按钮预约直播
3D视觉工坊哔哩哔哩也将同步直播
主讲嘉宾
 蒋擎
蒋擎
华南理工大学与IDEA研究院联合培养博士生
华南理工大学与IDEA研究院(粤港澳大湾区数字经济研究院)联合培养博士生,师从张磊教授。
-
研究领域:专注于多模态大语言模型、开集检测及计算机视觉前沿研究。
-
学术成果:在CVPR、ICLR、ICCV、ECCV、TPAMI等国际顶级会议与期刊发表多篇高影响力论文。
-
开源贡献:长期深耕AI开源社区,致力于构建高性能感知算法框架,个人及参与项目在GitHub累计收获超过16.6K Stars。
个人主页:https://mountchicken.github.io/
直播大纲
-
目标检测的现状与困境:传统检测器在闭集识别中的瓶颈。
-
基于MLLM的感知模型:大模型时代下视觉理解的新路径。
-
Rex-Omni的设计理念与数据构造:如何实现“检测万物”的架构创新。
-
Rex-Omni的实验结果分析:多项基准测试下的性能跨越。
-
Rex-Omni的下游应用场景:从学术研究到工业落地的新范式。
参与方式

注:3D视觉工坊很荣幸邀请到了华南理工大学与IDEA研究院联合培养博士生蒋擎,为大家着重分享他们团队的工作。如果您有相关工作需要分享,欢迎联系微信:cv3d009,请备注:宣传工作,则不予通过。
Rex-Omni工作详解
导读
对象检测长期以来一直由传统的基于坐标回归的模型主导,例如YOLO、DETR和Grounding DINO。尽管近期有研究尝试利用大语言模型来解决这一任务,但它们仍面临召回率低、预测重复、坐标对齐不准确等挑战。在这项工作中,我们填补了这一空白,提出了Rex-Omni,这是一种30亿参数规模的大语言模型,其在对象感知性能上达到了业界领先水平。在COCO和LVIS等基准测试中,Rex-Omni在零样本环境下取得了与基于回归的模型(如DINO、Grounding DINO)相当甚至更优的性能。这一成果得益于三项关键设计:
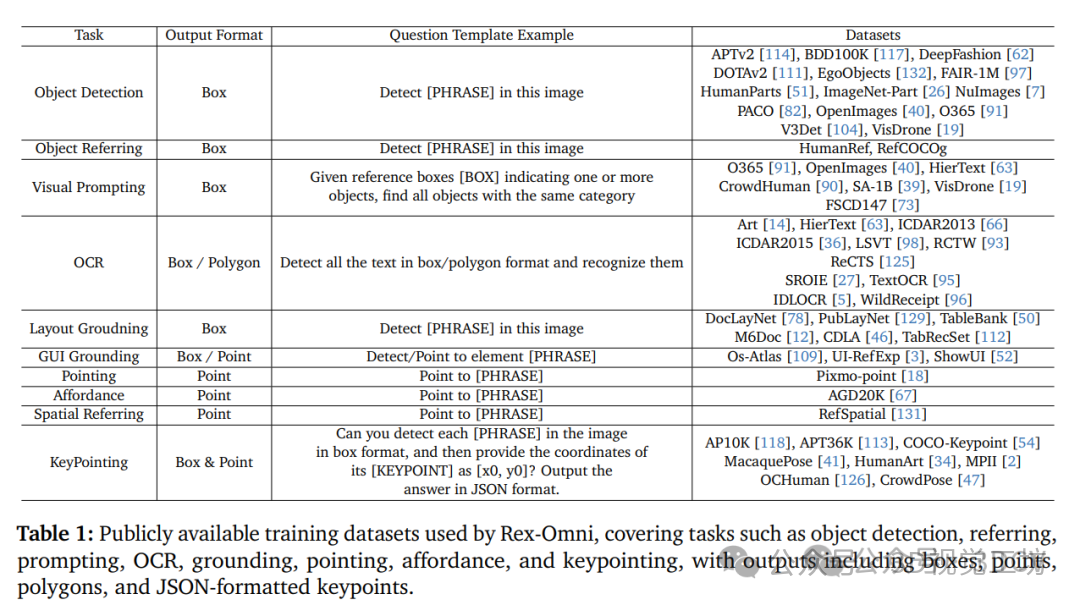
1)任务建模:我们使用特殊标记来表示0到999之间的量化坐标,从而降低了模型的学习难度,并提高了坐标预测的效率;
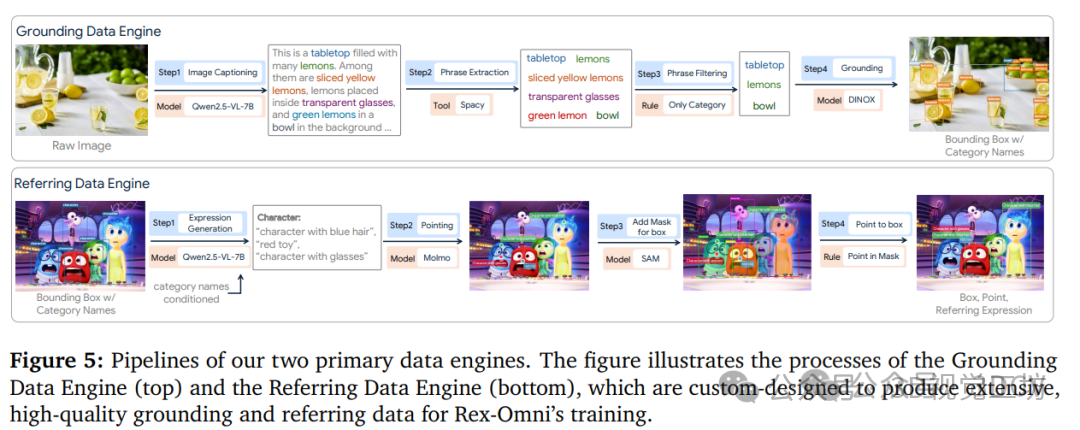
2)数据引擎:我们构建了多个数据引擎来生成高质量的对象定位、指代和指向数据,为训练提供了丰富的语义监督;
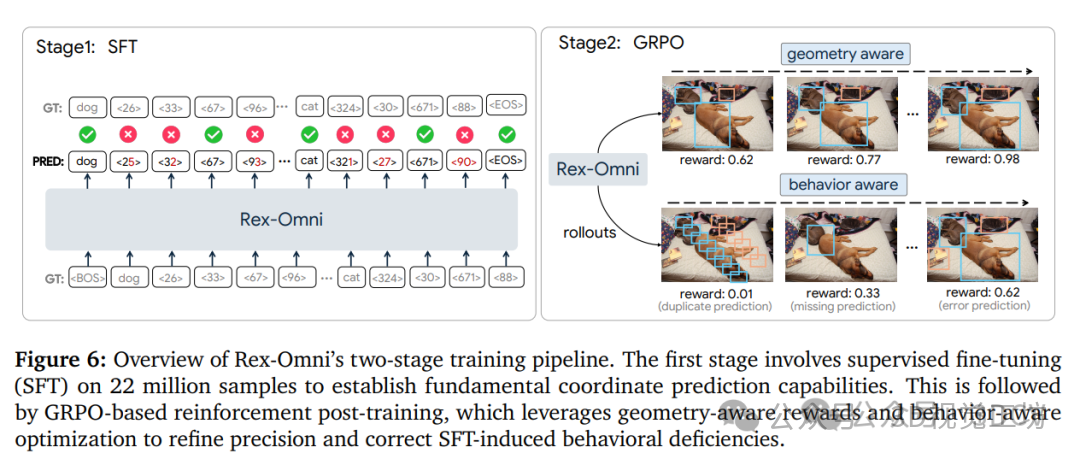
3)训练流程:我们采用了两阶段训练方法,先对2200万条数据进行有监督微调,然后通过基于GRPO的强化学习进行后期训练。
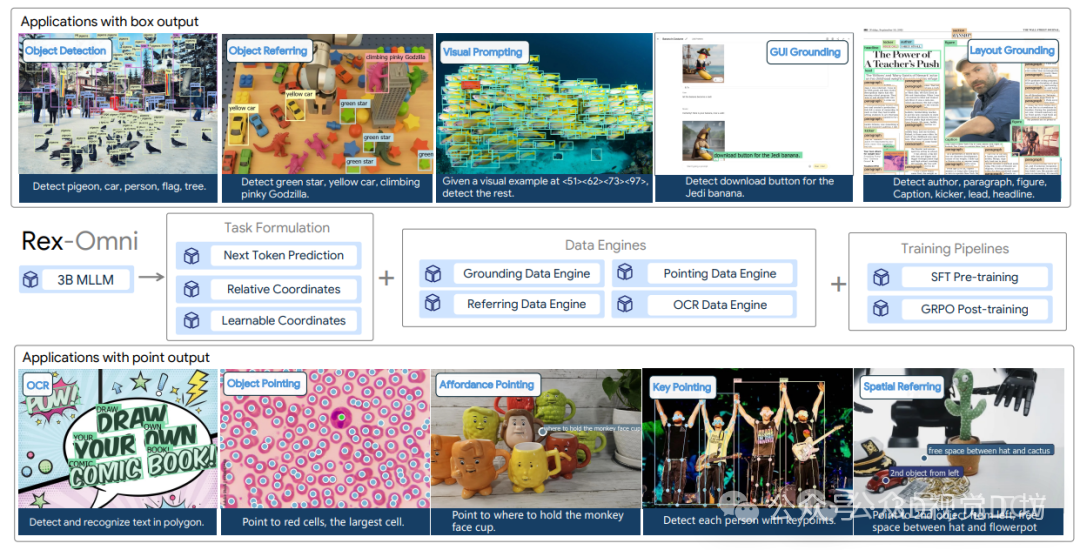
这种强化学习利用几何感知奖励有效弥合了离散坐标预测与连续坐标预测之间的差距,提高了框的准确性,并减少了由于初始SFT阶段的教师引导性质而导致的重复预测等不良行为。除了传统的检测功能外,Rex-Omni具备自然语言理解能力,因此能够实现对象指代、指向、视觉提示、GUI定位、空间指代、OCR和关键点提取等多种功能,这些功能都在专门的基准测试中得到了系统评估。
我们认为,Rex-Omni为更加通用且具备自然语言感知能力的视觉感知系统奠定了基础。
效果展示
我们提出了Rex-Omni,一种具有强大视觉感知能力的3B参数MLLM。
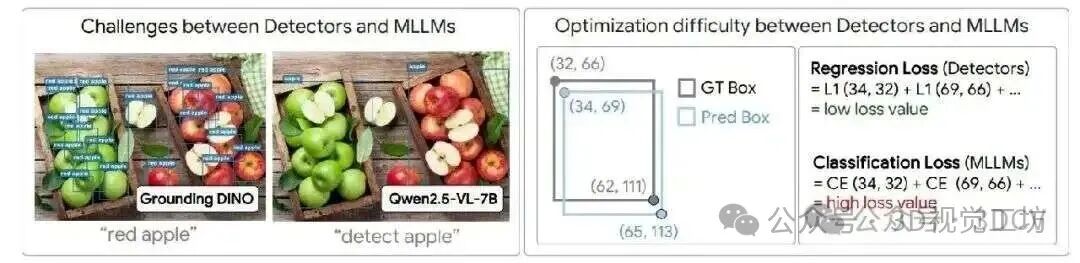
1)检测器在定位方面表现出色,但缺乏语言理解能力。MLLMs能够很好地理解语言,但在定位方面存在困难。2)检测器与MLLMs在优化难度上的差异。
主要贡献
Rex-Omni代表了向着统一鲁棒语言理解与精确视觉感知迈出的重要一步。通过精心整合原则性的任务公式、先进的数据引擎和复杂的双阶段训练流程,我们证明了MLLM在定义下一代目标检测模型方面具有巨大潜力,为视觉感知系统提供了前所未有的多功能性和真正语言感知的方法。
方法
如图4所示,Rex-Omni建立在Qwen2.5-VL-3B-Instruct模型之上,仅做了最小的架构修改。原始的Qwen2.5-VL采用绝对坐标编码方案,我们调整了模型以支持相对坐标表示,且未引入额外参数。具体来说,我们重新利用模型词汇表中的最后1000个标记作为特殊标记,每个标记对应一个从0到999的量化坐标。

实验结果
结果呈现在表2中。首先,在MLLMs中,Rex-Omni超越了包括之前拥有最先进检测性能的SEED1.5-VL在内的现有方法。在IoU阈值为0.5时,Rex-Omni表现出优越的性能,超过了开集检测模型Grounding DINO-SwinT和闭集检测模型DINO-R50。关键的是,Rex-Omni是在零样本设置下实现这一点的,这表明基于MLLM的检测方法在高度精确的边界框定位并非唯一关键因素时,确实可以超越传统的基于回归的模型。然而,在更严格的IoU阈值0.95下,Rex-Omni的性能虽然仍然强劲,但仅略微优于DAB-DETR,这表明在需要极高边界框紧密度的场景中,MLLM可能仍落后于传统的回归模型。
尽管如此,尽管存在这一细微的局限性,所取得的性能对于广泛的实际应用来说通常是足够的。我们在图7中展示了一些可视化结果。此外,经过GRPO后训练,完整的Rex-Omni模型显著优于其仅SFT的变体,观察到了明显的改进。这清楚地凸显了我们的强化学习策略的有效性。


总结
在这项工作中,我们介绍了Rex-Omni,一个拥有30亿参数的MLLM,它系统地解决了基于MLLM的目标检测所面临的挑战。通过使用特殊标记进行高效的坐标标记化、通过定制引擎进行大规模数据生成,以及新颖的SFT+GRPO两阶段训练流程,我们弥合了精确定位与深度语言理解之间的差距。我们的大量实验证明,Rex-Omni在广泛的视觉感知任务中实现了最先进或极具竞争力的零样本性能。关键的是,我们的分析验证了,虽然SFT提供了坚实的基础,但基于GRPO的后训练对于纠正SFT引发的行为缺陷(如重复和过大框预测)至关重要,这是构建鲁棒的基于MLLM的检测器的一项关键贡献。尽管性能强劲,但诸如推理速度等限制仍然存在。我们相信,未来在模型加速和高级奖励引导采样方面的工作将是关键的后续步骤。总之,Rex-Omni代表着向前迈出的重要一步,证明了MLLM的行为和几何限制可以被系统地克服,从而为下一代多功能、语言感知的感知系统铺平道路。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉方向论文辅导来啦!可辅导SCI期刊、CCF会议、本硕博毕设、核心期刊等。



添加微信:cv3d001,备注:姓名+方向+单位,邀请入群。
更多推荐


 0
0 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)