

rgb 光谱 转换
Finding an applicable cost-effective way to convert and use hyperspectral images.
寻找一种适用的具有成本效益的方法来转换和使用高光谱图像。
Authors: Abhiruchi Bhattacharya, Rishabh Karmakar, Soham Hans, Munagala Naga Govardhan.
作者:Abhiruchi Bhattacharya,Rishabh Karmakar,Soham Hans,Munagala Naga Govardhan。
Mentored By: Dr. Nidhi Chahal, Dr. Manoj Sharma
指导者:Nidhi Chahal博士,Manoj Sharma博士
介绍 (Introduction)
Hyperspectral imaging is a method of capturing various wavelengths of electromagnetic rays. The goal of hyperspectral imaging is to obtain the spectrum for each pixel in the image of a scene. Different forms of matter have different spectral properties and capturing these variations gives more information about the nature and qualities of the objects in the image.
高光谱成像是一种捕获各种波长的电磁射线的方法。 高光谱成像的目标是获得场景图像中每个像素的光谱。 不同形式的物质具有不同的光谱特性,捕获这些变化可提供有关图像中对象的性质和质量的更多信息。

Hyperspectral images can find applications in various computer vision domains including recognition [1][2][3], tracking[4][5], document analysis, and pedestrian detection[6][7].
高光谱图像可以在各种计算机视觉领域中找到应用,包括识别[1] [2] [3],跟踪[4] [5],文档分析和行人检测[6] [7]。

The hardware necessary for hyperspectral is very expensive and hence only a limited amount of hyperspectral images are available. Producing high spectral resolution also takes longer periods of exposure and therefore cannot capture moving objects.
高光谱所需的硬件非常昂贵,因此只能使用有限数量的高光谱图像。 产生高光谱分辨率也需要更长的曝光时间,因此无法捕获运动物体。
提案 (Proposal)
We aim to use deep learning methods to convert normal images captured using RGB cameras directly into hyperspectral images with high speed and low cost. Due to the ease of acquiring RGB images, it becomes easy to produce hyperspectral images for any kind of image analysis.
我们旨在使用深度学习方法将使用RGB相机捕获的正常图像直接转换为具有高速度和低成本的高光谱图像。 由于容易获得RGB图像,因此很容易生成用于任何图像分析的高光谱图像。
We develop various deep learning models for the direct conversion of RGB images to hyperspectral. These include techniques such as Convolution Neural Networks, auto-encoder models, and GAN models. We also explain the characteristics and performance of each of these models.
我们开发了各种深度学习模型,用于将RGB图像直接转换为高光谱。 这些包括卷积神经网络,自动编码器模型和GAN模型等技术。 我们还将解释每种模型的特征和性能。

楷模 (Models)
Pix2HS
Pix2HS
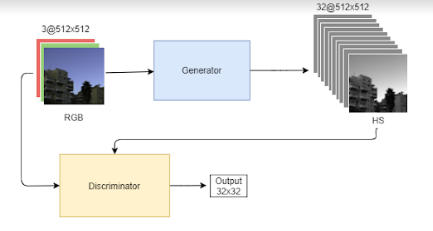
This is a GAN(Generative Adversarial Network) model based on the Pix2Pix[8] model. The model consists of 2 parts, the generator, and the discriminator.
这是基于Pix2Pix [8]模型的GAN(通用对抗网络)模型。 该模型由两部分组成:生成器和鉴别器。
The generator is composed of a ResNet[9] based model which takes an input 512x512 RGB image and converts it into a hyperspectral image with the same dimensions and 31 channels.
生成器由基于ResNet [9]的模型组成,该模型获取输入的512x512 RGB图像,并将其转换为具有相同尺寸和31个通道的高光谱图像。
Each of the channels represents the spectral image on a particular wavelength.
每个通道代表特定波长的光谱图像。

The discriminator is derived from the PatchGAN[8] model. It takes as input the predicted Hyperspectral image from the generator and the original RGB image as input. The PatchGAN model splits the images into patches and predicts whether each of the patches is real hyperspectral images or fake.
鉴别器来自PatchGAN [8]模型。 它以生成器的预测高光谱图像和原始RGB图像作为输入作为输入。 PatchGAN模型将图像分割成小块,并预测每个小块是真实的高光谱图像还是伪造的图像。

The job of the Generator is to fool the discriminator into thinking its images are real and the job of the discriminator is to make sure it can correctly differentiate between real and fake images. Both models are trained.
生成器的工作是欺骗鉴别器,使其认为其图像是真实的,鉴别器的工作是确保其可以正确区分真实图像和伪图像。 两种模型都经过训练。
CycleR GAN
甘R
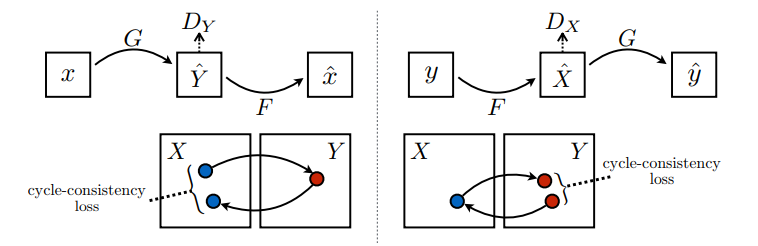
The Cycle Generative Adversarial Network[10][11], or CycleGAN, is an approach to training a deep convolutional neural network for image-to-image translation tasks.
循环生成对抗网络[10] [11]或CycleGAN是一种训练深层卷积神经网络以实现图像到图像翻译任务的方法。
The model architecture consists of two generator models: one generator (Generator-A)[12][13] for generating images for the first domain (RGB) and the second generator (Generator-B) for generating images for the second domain (HyperSpectral)
该模型体系结构包含两个生成器模型:一个生成器(Generator-A)[12] [13]用于生成第一个域(RGB)的图像,第二个生成器(Generator-B)用于生成第二个域的图像(HyperSpectral) )
- Generator-A to RGB Generator-A转RGB
- Generator-B to Hyperspectral 发生器B到高光谱

The generator used for this model is based on the U-Net[13] model. The generator models perform image translation, meaning that the image generation process is conditional on an input image, specifically an image from the other domain. Generator-A takes an image from Hyperspectral as input and Generator-B takes an image from RGB as input.
用于此模型的生成器基于U-Net [13]模型。 生成器模型执行图像转换,这意味着图像生成过程取决于输入图像,特别是来自其他域的图像。 生成器A从高光谱获取图像作为输入,生成器B从RGB获取图像作为输入。
- Hyperspectral to Generator-A to RGB 高光谱到Generator-A到RGB
- RGB to Generator-B to Hyperspectral RGB到Generator-B到高光谱
Each generator has a corresponding discriminator model. The first discriminator model (Discriminator-A) takes real images from RGB and generated images from Generator-A and predicts whether they are real or fake. The second discriminator model (Discriminator-B) takes real images from Hyperspectral and generated images from Generator-B and predicts whether they are real or fake.
每个生成器都有一个对应的鉴别器模型。 第一个鉴别器模型(Discriminator-A)从RGB拍摄真实图像,并从Generator-A生成图像,并预测它们是真实的还是假的。 第二个鉴别器模型(Discriminator-B)从高光谱中获取真实图像,并从Generator-B中生成图像,并预测它们是真实的还是伪造的。
- RGB to Discriminator-A to [Real/Fake] RGB至鉴别器-A至[实/假]
- Hyperspectral to Generator-A to Discriminator-A to [Real/Fake] 高光谱到发生器A到鉴别器A到[真实/伪造]
- Hyperspectral to Discriminator-B to [Real/Fake] 高光谱到鉴别器-B到[实/假]
- RGB to Generator-B to Discriminator-B to [Real/Fake] RGB到生成器-B到鉴别器-B到[实/假]
Together, each pair of generator models are trained to better reproduce the source image, referred to as cycle consistency.
一起训练每一对生成器模型,以更好地重现源图像,称为循环一致性。
- Hyperspectral to Generator-A to RGB to Generator-B to Hyperspectral 高光谱到发生器A到RGB到发生器B到高光谱
- RGB to Generator-B to Hyperspectral to Generator-A to RGB RGB到Generator-B到高光谱到Generator-A到RGB
HyperCNN
超级神经网络
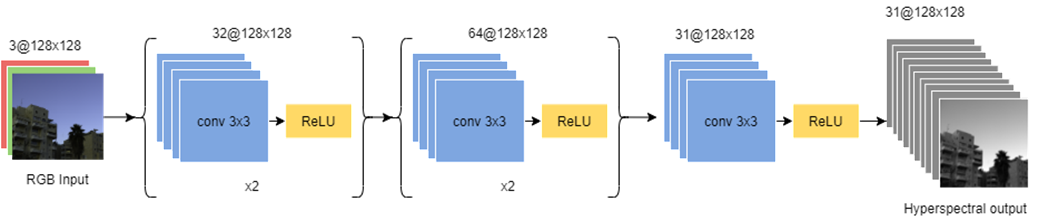
Convolutional neural networks find widespread applications in image processing and computer vision. CNN’s are effective for hyperspectral recovery[20][27]. Hence, we first consider a five-layer CNN model. The number of feature maps for the first two layers is kept as 32, while for the next two as 64. The final layer produces the 31 channel output image. ReLU activation is used after each layer.
卷积神经网络在图像处理和计算机视觉中找到了广泛的应用。 CNN对于高光谱恢复有效[20] [27]。 因此,我们首先考虑一个五层的CNN模型。 前两层的特征图数量保持为32,而后两层的特征图数量保持为64。最后一层生成31通道的输出图像。 每层之后都使用ReLU激活。
Preprocessing and Hyperparameters: The dataset images were resized to128x128 and normalized between -1 and 1. Kernel size for all layers is 3. Adam optimizer was used for training, with an initial learning rate of 0.0001. The model was trained for a total of 30 epochs with batch size 4.
预处理和超参数:数据集图像的大小调整为128x128,并在-1和1之间进行归一化。所有层的内核大小为3。Adam优化器用于训练,初始学习率为0.0001。 对该模型进行了总共30个时期的训练,批次大小为4。
CA-Net
网络
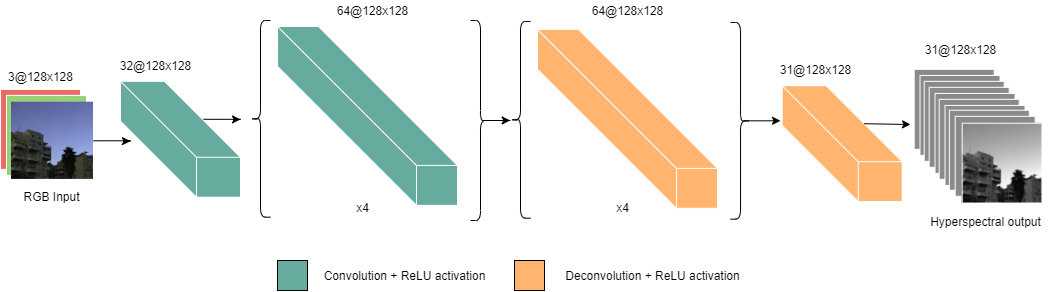
Convolutional autoencoders are networks that typically find applications in noise removal, supersampling, and unsupervised feature extraction[28].
卷积自动编码器是一种通常在噪声去除,超采样和无监督特征提取中找到应用的网络[28]。
Autoencodernetworks work by extracting (i.e. encoding) a compact representation of the input data and recreating (decoding) the output using that compact representation.
自动编码器网络通过提取(即编码)输入数据的紧凑表示并使用该紧凑表示重新创建(解码)输出来工作。
We define two autoencoder-based models, namely CA-Net 5 and CA-Net 10.CA-Net 5 consists of five convolutional and deconvolutional layers, with ReLUactivation after each layer. CA-Net 10 is a deeper version of the former, with ten convolutional and deconvolutional layers respectively.
我们定义了两个基于自动编码器的模型,即CA-Net 5和CA-Net10。CA-Net5由五个卷积和反卷积层组成,每层之后都有ReLUactivation。 CA-Net 10是前者的更深版本,分别具有十个卷积和反卷积层。
Pooling and un pooling operations are omitted to preserve details in the hyperspectral image. In both cases, the final layer is modified to return the generated hyperspectral image with 31 channels.
省略池化和取消池化操作以保留高光谱图像中的细节。 在两种情况下,都修改了最后一层以返回具有31个通道的生成的高光谱图像。
结果 (Results)

The pix2HS GAN achieves a validation set MAE of 0.014. The model also is computationally less expensive due to the fewer layers in the generator when compared to a traditional CNN model.
pix2HS GAN的验证集MAE为0.014。 与传统的CNN模型相比,由于生成器中的层数较少,因此该模型的计算成本也较低。
The CycleR GAN model achieved a training MAE of 0.024 and a validation set MAE of 0.038. The lesser accuracy could be contributed to the conflicting shape of the two data — 3 for RGB to 31 for Hyperspectral.
CycleR GAN模型实现了0.024的训练MAE和0.038的验证集MAE。 精度较低可能导致两个数据的形状冲突-RGB为3,高光谱为31。
The HyperCNN model achieved a training loss of 0.015 and a validation loss of 0.021. The training and validation losses stabilized after approximately 20 epochs. The images produced from the validation set retained most details and contained minimal distortion.
HyperCNN模型的训练损失为0.015,验证损失为0.021。 训练和验证损失在大约20个纪元后趋于稳定。 验证集生成的图像保留了大多数细节,并且失真最小。
The CA-Net 5 achieved a training loss of 0.0164 and a validation loss of 0.018, performing the best among the convolutional models considered. Overall the model tends to produce slightly darker images for higher channels, and slight aberrations can be seen for some edges.
CA-Net 5的训练损失为0.0164,验证损失为0.018,在所考虑的卷积模型中表现最佳。 总体而言,该模型往往会为较高的通道生成稍暗的图像,并且在某些边缘会看到轻微的像差。
The CA-Net obtained a training loss of 0.023 and a validation loss of 0.029.
CA-Net的训练损失为0.023,验证损失为0.029。

结论 (Conclusion)
We have presented multiple models to convert RGB image inputs in 3 channels to 31 spectral channels with high accuracy. We have shown that our models can accurately and efficiently develop hyperspectral images from RGB data. Our methods also have very little run time and computational complexity. We have shown a variety of approaches and the pros and cons of each.
我们提出了多种模型,可以将3个通道中的RGB图像输入高精度地转换为31个光谱通道。 我们已经表明,我们的模型可以从RGB数据中准确有效地开发高光谱图像。 我们的方法运行时间和计算复杂度也非常低。 我们展示了各种方法以及每种方法的利弊。
Future work can be done to further increase the accuracy of hyperspectral imaging so that these methods can truly replace all hyperspectral cameras and revolutionize the field of computer vision and analysis from images. Converting RGB images to IR can be another domain in which this research can be useful for future reference.
可以做进一步的工作来进一步提高高光谱成像的准确性,以便这些方法可以真正替代所有高光谱相机,并彻底改变计算机视觉和图像分析领域。 将RGB图像转换为IR可能是另一个领域,这项研究可以为将来的参考提供帮助。

rgb 光谱 转换






 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)